CS3134 Homework #6
Due on Monday December 13, 2004: written must be
submitted by 5:00pm in 608 CEPSR or the dept. front office, and programming
must be submitted electronically by 11:59:59pm.
There will be no late days accepted on this assignment as it is due
on the last day of the semester.
There are two parts to this homework: a written component worth
10 points, and a programming assignment worth 15 points (plus extra credit
of up to 7 points). See
the homework submission
instructions on how to hand it in and for important notes on
programming style and structure.
Written questions
- (2 points) You're given the following list of numbers to
work with.
48, 21, 45, 1, 93, 87, 55, 100, 34, 97
- (1 point) Insert the numbers into a
heap and draw the result (in tree form). Assume larger numbers are
of higher priority.
- (1 point) Draw the
heap after one call of removeMax is executed.
- (5 points) Undirected/unweighted graphs.
- (3 points) Draw a 5-vertex, 5-edge undirected, unweighted graph, with
no vertex incident (i.e., connecting) to more than three edges,
that can produce the following BFS and DFS. You can assume there are no
“double edges” between a pair of vertices (e.g., every edge connects a
unique pair of vertices), and that BFS and DFS don't need to work "in
the same order" (i.e., starting at A, they can pick any edge incident to
it when starting their search).
BFS: A B D E C
DFS: A D E C B
- (2 points) How many spanning trees exist for this graph? (You
don't need to draw each of them, just explain how you derived that
number.)
- (2 points extra credit) Can you think of a way of
algebraically expressing an upper bound for the number of spanning trees
for a graph given the # of edges and the # of vertices in the graph?
- (3 points) Given the following graph:
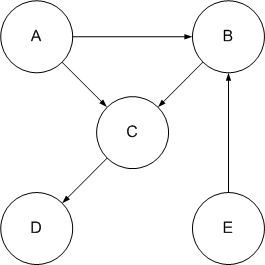
- (1 points) List the vertices in topological order. Is
this the only topological ordering for the graph? Explain
in one or two sentences why.
- (2 points) Draw the adjacency matrix for the graph.
Compute its transitive closure via Warshall's algorithm, and
draw the resulting connectivity matrix. Are there any
cycles in this graph? Explain in a sentence why or why
not.
Programming problem
In this programming assignment, we're going take the concept of processing
emails from HW#5 and use graph concepts to solve a related problem:
determining relationships between people by examining email headers.
For example, if I have an email sent from A to B and another one sent
from C to B, I can say that that A and C communicate "through" B.
Your goal is to write a program that uses depth-first search to
support "searching" this web of connections to find paths between email
addresses.
To do this, we're going to replace the Tree and EmailHeader class from
HW#5 with a combination of a HashMap and a graph to enable quick lookup
and traversal. One key difference between the book and this
homework is that we will implement the graph as a collection of
EmailAddress objects and references between them, not as an
adjacency matrix. Here's what you should do:
- (4 points) Create an EmailAddress class.
- (1 point) It will have three fields:
- A String representing the actual email address;
- An ArrayList of friends (ArrayList is a class in
java.util that
functions similarly to a LinkedList, but supports an array-backed
list).
- A boolean representing whether or not this node has been visited
before (defaults to false).
- (1 point) Write a method called addFriend that takes
another EmailAddress object and adds it to our list of
friends if it's not there already.
- (2 points) Write a method called getUnvisited that
searches our list of friends for an EmailAddress that has
not yet been visited, and returns it. If there aren't any,
return null.
- (8 points) Write an EmailList class.
- (1 point) Declare a HashMap of EmailAddress objects
(HashMap is a class in java.util that implements a
key-value pair-based hash table).
- (1 point) Write a method called normalizeAddress that takes
a String and extracts and returns only the email part of it.
For example, it should convert "Janak J Parekh <janak@cs.columbia.edu>"
to "janak@cs.columbia.edu". If there are
multiple addresses in the string, it should only keep the first one. Note that some addresses may
appear in the latter form by default, so you'll have to play with this
and make it sufficiently flexible. Also make sure it converts the
email address to lowercase. (Tip: the String method split
or StringTokenizer can be used to do this. I find that if you call
original.split("(<|>|,)"); you tend to get pretty good results
-- the email address is then contained in either the first or second
cell of the resulting array. Write a little test program to figure
out the optimal way of setting this up.)
- (1 point) Create a method called addPair that takes two
email addresses in String form. It should first normalize these
addresses using the previously-defined method. Then, for each
normalized address, it should try and look it up in (get from)
the HashMap, and if it's not in there should create new
EmailAddress objects and put them in the HashMap.
It should then mutually call addFriend on each of the objects
(i.e., the first one adds the second one as a friend, and the second
adds the first as a friend).
- (1 point) Write a method called resetVisited() that goes
through all the EmailAddresses and resets their visited values
to false. Since the EmailAddress objects are
contained in a HashMap, this is a little tricky; the way to do
it is to a execute a set of nested calls that extracts the values from the
HashMap. If the HashMap is called hm, you
can
run hm.values().iterator(). You'd be given an
Iterator object with the ability to "walk" through each of the
EmailAddresses. Alternatively, hm.values().toArray()
converts the results to an array, but of type Object[].
In either case, you need to cast individual objects to type
EmailAddress before you set their visited value.
- (4 points) Write the depth-first search methods. Write one
method that takes email addresses in String form, looks them up
in the HashMap, and obtains the corresponding the
EmailAddress objects. If they don't exist, it should print an
appropriate error and return. Otherwise, it should call a
second DFS method with the
source and destination EmailAddress objects.
This second DFS method takes those two parameters. It
first resets the visits of all the EmailAddress objects using the
method described in #4. It then actually does the DFS:
- First, it creates a new empty stack using the Stack class
(once again, in java.util).
- Second, it uses this Stack to implement depth-first search
as described in class in great detail on 11/30. (If you weren't
there, either use the book as a model, or make sure you get the notes
from someone -- the main difference is that it uses object references
and not an adjacency matrix, and that it "stops" when the match is
encountered if any.)
- Third, if it doesn't find the destination, it prints an error
message saying that there is no path between the two specified email
addresses. If it does find the
destination, it instead prints out the contents of the stack, which
serves as the path. To do this, use stack.iterator() or
stack.toArray() in a strategy similar to #4. It will
automatically "reverse" the contents, making it easy to print it in the
right order.
Neither DFS actually returns any value - it just prints out a result
as appropriate.
- (3 points) Write an EmailGrapher "app" class with one
method: main. You can adapt your EmailSearcher
class, as you will again be processing email files. If you didn't
like your homework submission, Janak's solutions for HW#5 will be
released on Thursday, 12/2.
- (2 points) Have EmailGrapher create an object of type
EmailList with which you will insert data and call DFS.
Modify the parser routine so it only keeps track of the headers, and
only From: and To: at that. As soon as it
finishes processing a header, it should call EmailList's
addPair method. (You no longer need the EmailHeader
class!)
- (1 point) Instead of asking for one word, ask the user for two email
addresses on one line, separated by a space. Split them, and call
your EmailList's DFS with the two parameters (which
will then print out the result). Again, quit if the user doesn't
enter anything.
- (Up to 5 points extra credit) Add the following functionality
to your assignment.
- (2 points) Keep a count of every time an email address appears in an
email -- this is most easily done by modifying the addFriend
method, as that's called every time an email address appears.
Then, modify EmailList to print out the top 10 most appearing
email addresses, and modify EmailGrapher to show this before
you ask the user for input.
- (3 points) Instead of only tracking one To: address (the
first one), track multiple To: and Cc:
addresses. This means setting up a relationship between the
From: and all of the destinations (for simplicity's sake,
don't make connections between the destinations themselves).
In short, this means you'll have to normalize the addresses more
carefully, and modifying addPair in the process.
Tips:
-
Once again, use Javadocs to your advantage. You'll be using three
generic Java data structures:
ArrayLists,
HashMaps, and
Stacks. You can click on each of those hyperlinks to see a
Javadoc of the appropriate class. If you're not sure how to use one of
them, consider writing a little tester program where you add and remove a
few things until you get the hang of it.
- As a result, you won't actually be doing the data structure work itself
for those three -- only for the graph component. For example, you
don't have to worry about the hash function for Strings.
- Don't forget that pulling any piece of data out of a Java data structure
requires a cast before you can use it in any meaningful fashion.
- Test against your email! You can see where your Inbox is located
on CUNIX by typing "echo $MAIL", or can look in ~/mbox
or ~/mail for additional mail files. I will provide a
reference test email file once I've sufficiently hidden away sensitive data;
I'll post this up by 12/2 along with the HW#5 solutions.