Our group decided to focus on developing constructive strategies, which are enumerated as follows:
A "blind" strategy is one that statically defines robot movement based on the initial board conditions (e.g. number of robots, players, etc). Some examples of such a strategy are the "Grid", "Army", and "Ladder" strategies. Blind strategies are easily implemented and can be highly efficient at completing a simple task.
A preliminary strategy, "Cavalry", was completely blind, implementing a static patten of robot movement. Its successor and our first player, "Annealing Cavalry", started as a blind strategy incorporating a similar pattern of movements, but it modified said movements throughout the game in a predefined manner.
"State-Aware" strategies determine robot movement based on the current board state during any given round. The "board state" includes such aspects as filled and unfilled cells, previously drawn lines, and those cells filled by opponents. These strategies can be very effective, especially in multi-player games, where analyzing robot movement becomes difficult.
Our second player, "Royal Cavalry", began as a "state-aware" strategy, adapting its robot movements according to what cells were already taken.
"Fully-Aware" strategies incorporate the positions of opponents' robots into decision making. A good example of such a strategy is the common "Chaser" strategy.
While our second player, "Royal Cavalry", did not implement any chasing strategies, it did attempt to combat such an opponent by adapting to "threats" and changing robot behavior.
As stated above, the strategy of our first player, "Annealing Cavalry", began as a blind strategy, before the anti-chaser strategy was added. It never called functions like allRobots(), colors(), or filled(). Robots always follow fixed trajectories (except for some initial randomness).
As defined by the dictionary program WordWeb 1.63:
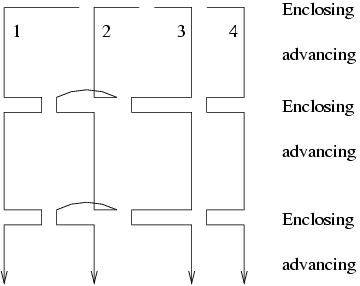
As indicated by the name, the basic idea of the "Cavalry" strategy came from the "Army" strategy. Robots sweep the board with certain distances between them, and after certain steps they move together to enclose areas that they have swept. The following figure illustrates the Cavalry strategy:
In the "Annealing Cavalry", the moves of robots looks like this:

In the "Royal Cavalry", the implementation is more general. The distances between a pair of consecutive robots can be different to each other, which are pre-defined at the begining of this mission. (See the program architecture for missions.) During the game, one or more chased robots may be dropped from the cavalry while other robots can still continue the cavalry mission.
The "Royal Cavalry" switches between two stages: advancing and enclosing. At the advacing stage, all robots keep in a row, sweep the screen in a same pace. At the enclosing stage robots make up a line from the left-most robot to the right-most robot in order to get some scores.
The core adaptive quality is determined by a question: How many steps should the cavalry advance between two enclosing stages?
In the "Annealing Cavalry", it is determined by the width between two adjacent robots, which is in turn determined by the board size and the number of robots. However, in "Royal Cavalry", robot movement is more intelligent (i.e. it is more adaptive). At the start of the mission, we pre-define four possible values for the number of advancing steps between two "enclosing" stages:
| minimum | the minimum allowed |
| standard | the number if danger is detected |
| extended | the number if there is no apparent danger |
| maximum | the maximum allowed |
Damage detection After advancing for at least the minimum distance, if the program finds the start line or one of the two side lines are damaged by other robots, it switches to the enclosing stage immediately.
Danger detection If the robots have advanced for at least the standard distance, and the program found the start line is in danger, it would be ready to switch to the enclosing stage. Otherwise, the robots must advance for at least the extended distance before considering switching to the enclosing stage. The program checks the location of the nearby robots and their last move, and use an algorithm to compute the "danger" value.
If the "Royal Cavalry" is ready to switch to the enclosing stage, it might not switch immediately. Instead, it will find a best enclosing line. The current algorithm makes use of the number of black squares in a line. If a line contains no black squares, it could be the best enclosing line. Otherwise, the line's value deteriorates with increasing numbers of black squares.
We are not satified with this algorithm of finding the best enclosing location. There are better algorithms to find the best enclosing location (e.g. calculating gain versus cost or gain versus risk), but we did not have time to implement them.
Once in the enclosing stage, if the start line or one of the two side lines are damaged, the nearest robots in the cavalry will go back to repair the line, if it can be done in pre-configured steps. The other robots will continue to make the enclosing line without them. Some robots may also abandon the cavalry because they are being chased, and other robots can still finish the mission. (Note: the cavalry will never dismiss robots, though the rect mission may, as seen below.) In order to fill a line with any number of robots, we developed an algorithm to find the optimal solution. The following figure illustrates a scenario in which one robot tries to repair a line while others are enclosing:
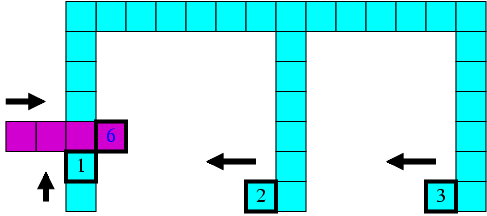
In such cooperative strategies, synchronization is a significant problem. Other robots may stay stationary while waiting for one robot to finish its work. In order not to slow down the progress very much, we give deadlines for enclosing or repairing work (as also in other missions and quests). We also planned to give a deadline to the entire cavalry mission so that robots may directly match to the end of the line and enclose there, while the deadline is approaching, though we did not have time to implement that feature.
The end-game strategy in the "Annealing Cavalry" is quite simple: the distance between two adjacent robots will be decremented after a complete scan of the board. After several turns it will completely transform into an "Army" strategy. The "Army" strategy, in turn, is probably one of the best end-game blind strategies, because of its consistency in collecting small squares at the end of the game. The "Army" Strategy is a known quantity, so we will focus on the end-game strategy that the "Royal Cavalry" adopted, "Rectmania".
This was the work done in last 24 hours before due, and we are glad to see it works at least as well as previous end-game strategies. We found that most end-game strategies are comprised of a similar objective: to search for rectangles and to paint them. Thus, it is not surprising that we noted a few of of both this and last year's groups have a similar behavior, although we did not have enough time to analyze those programs to discover the exact differences.
There are plenty ways to search for available rectangles. Some can be found in the mediator program, in programs from the previous class, and in the players of other groups. We tried to find the best method by concentrating on being as efficient as possible. We divided rectangles into two classes: those that contain black squares and those that do not. Clearly, the former has a higher average profit-to-cost-ratio. Therefore, we first search for the largest rectangles in the first class that can be completed efficiently, and only if we find none, we search for those of the second class. Please consult the algorithm section below for details.
We used an algorithm based on Abhinav's algorithm posted on the web-board. Much is the same, though a few minor details are different. The algorithm is discussed below.
Robots in most of the programs will stop moving if they are chased, and "Annealing Cavlary" is no exception. However, in "Royal Cavalry", the robots will move randomly on squares which are neither white nor in their own color.
Strategies can always be improved — one can always tune and combine existing strategies, improve the effectiveness of simple or complex strategies, or just gain experience. What one actually does, then, must be based on one's objective. Our goal was always to explore new ideas and methods of implementation. So, we continued to develop the various forms of the "Cavalry" strategy, despite the fact it did not necessarily produce the "best" results. Interestingly, the more-advanced "Royal Cavalry" can lose to the "Annealing Cavalry" because the adaptive qualities hinders the pace of the robots.
When a robot is switching tasks, it might move from one place to the other. However in a rectangular grid, usually we have many paths to do that. So, it is possible to find a path that "destroys" more of the opponent-colored squares than others. This is an optimization problem: the evaluation function being the sum of all benefits that the robot go though a square. In our program the benefit that a robot go through a quare are defined to be the owner's current score of the square's color. If a robot goes through a black square, it gets no profit, and if a robot goes through a square in its own color, it gets only one point of benifit. The algorithm do not necessarily check all possible paths. (The number of paths is exponential to the distance!) It is actually a simple dynamic-programming problem, and can be done in O(b2), where b is the maximum of the differences of x-coordinates and y-coordinates between the current position and the destination position.
filled() matrix, in which black squares are represented by true, and others by false.This algorithm is clearly O(n2) where n is the board size.
(Note: For this algorithm, it is important to assume that all black holes are rectangles.
Since the number of black holes is usually much less than n2, and with the early termination conditions, its reasonable to estimate the mean running time is within the order of n2.
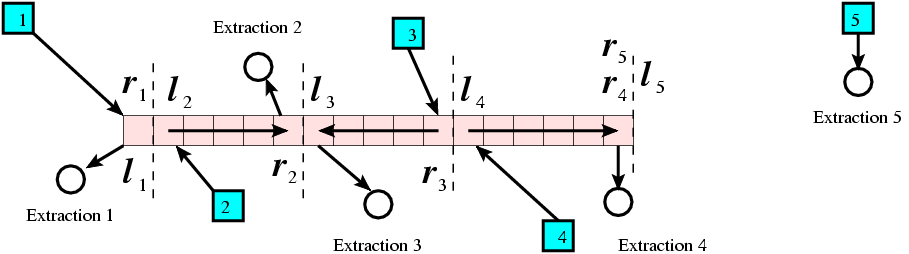
The problem of making up a line is generalized. Suppose we have d robots and a line to be painted. Each robot has an insertion point (its current position) and an extraction point (the place to go after the mission). Without loss of generality, we suppose the line is horizontally placed, with two end-points being (x0,y) and (xn,y). We also suppose that each of the robot is responsible for a segment of the line, because, if a robot can do two segments, it can do the minimum super segment of the two segements with the same cost.) It's also reasonable to assume that the nearest square to the robot is in the segement, if the robot actually has a segment to be responsible for. The following figure illustrates this scenario.
We found that, if we just use the maximum costs for all robots as the evalution value, the hill-climbing algorithm would easily reach a shoulder point. Then we changed the evaluation function to be in a format of A.B, where A is the previous maximum costs for all robots, and .B is 0.0001 multiplied by the sum of the costs of all robots. This change would not affect the optimal solution of the problem, but it will make hill-climbing much more effective. This kind of problem should be very general in the optimization research, so naturally we guess that it must have been invented and used in many problems.
This algorithm originated in Abhinav Kamra's post to the class web board. We added a few modifications and implementation details.
The running time of this algorithm is O(dm log(dm)), where d is the number of robots, and m is the number of unpainted squares. In the "Royal Cavalry" the extraction points are not implemented because they are not necessary.
All the previous algorithm are expected to be efficient. We think our program has an almost O(bn2) response time, where b is the number of robots, and n is the board size.
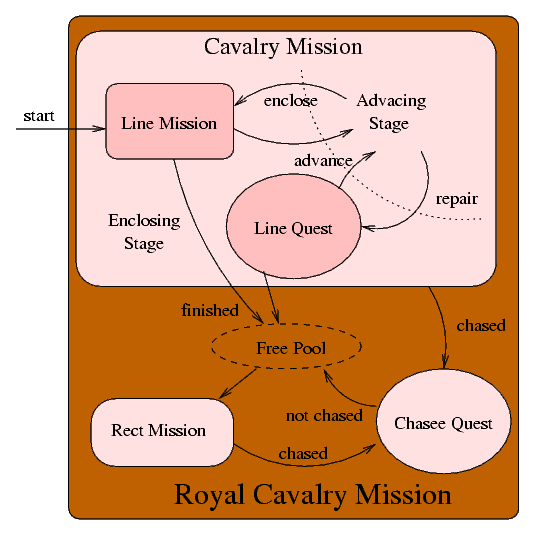
We implemented a task model for the "Cavalry" players. Each task can be initialized at any time and ends later, either actively or passively, and robots may be dynamically added or deleted from the task, either actively or passively. There are two kinds of tasks: tasks that can be accomplished by multiple robots, called missions, and tasks that can only be done by one robots, called quests.
The following figure is the state transmition diagram of robots in the "Royal Cavalry" which adopted this task model. We shall not describe this verbosely, please read the comments in the program if one is interested.
Another aspect we want to mention is that we implemented a "re-orientation mechanism". Using this mechanism, the board can be rotated, mirrored left-right, flipped top-bottom, x-y transposed, and transformed by any combinations of these operations (to make a total of eight combinations). Algorithms can be applied the virtual transformed board, so that we can easily implement orienation-sensitive strategy (such as the Cavalry) along any direction.
We used different terms while programming "Royal Cavalry". These terms helped name the classes, and the difference of terminology was seen as a preventative measure to help avoid namespace clashes. They are:
Here we itemize what we saw when we were debugging and testing our program. Some of these observations may be only related to the mediator program.
An initial goal of ours was to build a package of classes that could be easily used (and re-used) in the development of players. The diagram below shows the basic structure of the so-called "G5 Package", excluding sub-classes, in a hierarchical format. The oval shapes represent classes we considered to be "primitive" objects, meaning the building blocks of any program. The rectangle shapes represent classes we consider to be "complex" objects, meaning those that utilized instances of primitives in order to achieve an over-arching goal.
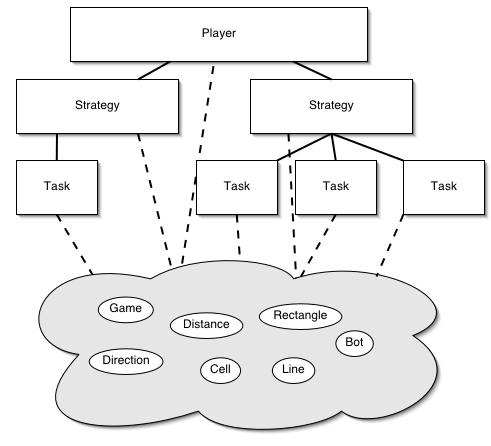
The package did prove to be a boon for development of complicated strategies and players, providing a level of abstraction not found in the game engine's interface. Furthermore, the modularity of the classes made it possible to dynamically and hierarchically combine different strategies, either sequentially or simultaneously. However, in retrospect, the cost (i.e. time spent) of initially developing the package was too high, and prevented us from submitting more of our ideas and players – we just didn't have time to complete the players. Below, we detail some of the work we did that we did not use in final players we submitted.
A task, for the purpose of the project, is distinct unit of work that will make the player better off score-wise if completed. One or more robots may be assigned to a given task. A task is not necessarily constructive; it may involve trying to prevent another player from getting points. This concept is an extension of last year's group 8's concept of men on mission, where there is one type of task, namely building a rectangle.
Each task has a specific time (measured in turns) to complete, chance of success, and payoff. Thus, once several mutually exclusive potential tasks are found, they can be ranked by a strategy, and the best tasks can be chosen. Some strategies might be more aggressive, trying to achieve riskier tasks with bigger payoffs, whereas others may be more conservative. These preferences may be determined not only by the strategy's innate characteristics, but may also be based on board size and density, as well as relative scores and early behavior of opponents.
The general framework of a task is as follows:
abstract class Task
{
void move(); // move member robots
boolean isFinished(); // is this task complete?
boolean isHopeless(); // can this task never be completed?
int expectedPayoff(); // how many points will we get from
// this task
float chanceOfSuccess(); // how likely are we to complete this task
void destroy(); // free robots for other tasks
void addRobot(int robot); // add specified robot to this task
void removeRobot(int robot); // add specified robot to this task
}
The initial task is the most important because the most available space exists at the beginning of the game. A player who capitalizes on this position gains a significant advantage that often determines the outcome of the game.
Our solution to this problem is to build a central square or rectangle at the beginning of the game, as discussed in class and used by group 6 from last year. We refer to this approach as the circle your wagons strategy.
To determine the size of the initial rectangle, we calculate how many turns we think we'll have to complete a central square based only on board metrics (number of players, number of robots, and total number of squares on the board). The specific formula we use is:
N = allowed_turns = ln(board_size^2)+.5which was determined experimentally from some testing with different board sizes and numbers of robots.
Once the number of turns available has been set, we place our robots spaced N spaces apart around the board's center in a square, or a rectangle if the number of robots will not form a square evenly. (The more squarelike the initial rectangle, the higher the yield of points per robot.) Thus we are assured of completing this rectangle in N moves, assuming no interference by other players.
Given this placement, the robots walk clockwise around the rectangle continually until either it has been completed or it is hopeless. We define a rectangle to be hopeless if either a box on its perimiter is been black, or if 3*N turns have elapsed since starting it and it is still not complete. This time limit is imposed so that if one robot is being chased, the other robots will not all be perpetually stuck working on a task that will never be completed. In the future, it would be more useful to have a test for each robot to check if it is being chased and take itself out of the rectangle instead of having the timer.
The wagons strategy produced strong results with the default board size and number of robots, but is dependent on other players not interfering with the initial rectangle. In a two-player game, the strategy generally resulted in a large initial score quickly, as in this example:

Note that the army player's use of robots is highly inefficient compared to the rectangle's. The army player has captured just 32 points in 60 robot-turns of work (20 robots working for 3 turns = 60 robot-turns), or a little more than .5 points per robot-turn (PPRT). By comparison, the wagons player has captured 361 points in an equal amount of work, translating to over 6 PPRT.
Even with a larger number of opponents, this strategy often pays off:
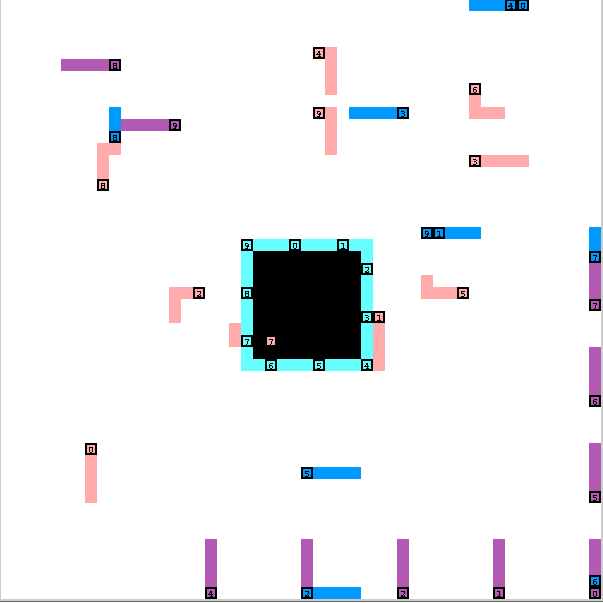
However, this strategy does suffer with a large number of robots, even when the opponent is not pursuing a defensive strategy. For example, here is a standard-size board with 40 robots per team.
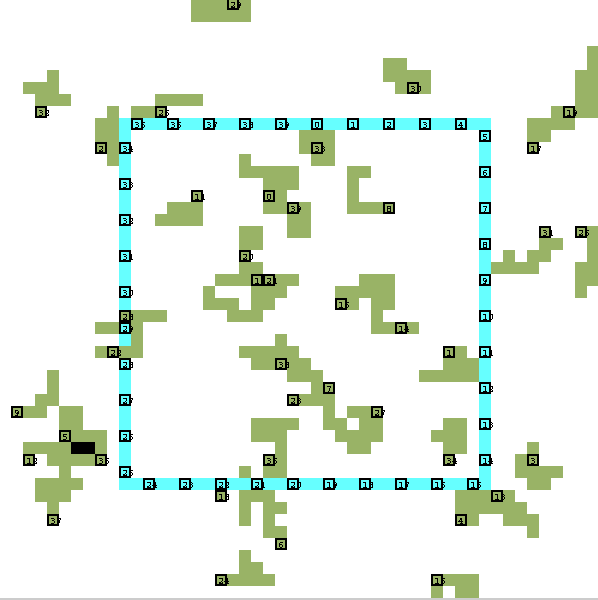
Note that the expected time to complete this rectangle was calculated to be three turns, yet even after twelve turns, there has still been too much random interference to complete it. (In this example, it took 33 turns before the internal square could be completed.) Unfortunately, it appears that merely reducing the size of the initial rectangle does not help significantly -- there are enough robots on the board to prevent even smaller squares from being formed.
One potential answer to this situation would be to try for several smaller squares, with the knowledge that some would not be completed, but with the hope that enough would be completed to still provide a significant advantage.
Another improvement on the wagons strategy would be to randomize the start position. This would avoid the problem of enemies prepositioning a robot such that it will disrupt our initial rectangle.
A logical outgrowth of the initial rectangle task is a generalized rectangle task, where one or more robots work together to complete an arbitrary rectangle. A general rectangle task differs from the initial rectangle task in the following ways:
Since completing rectangles is the goal of the game, and completing them efficiently can maximize one's PPRT, we devised an algorithm which we believe will always optimally trace any given rectangle, given that all the robots involved are already on the rectangle's edge:
(Note: this algorithm does not account for the possibility that one can travel through the interior of the rectangle to get to the other side. However, our experience suggests that except for certain unusual cases, the turns saved by cutting through the rectangle are small or nil.)
Implementing optimal rectangle tracing is one component of the larger strategy of evaluating possible rectangles and choosing to complete the best ones. We did not implement an algorithm to intelligently choose rectangles, and thus we did not have a strong strategy involving optimal rectangle tracing. We borrowed a rectangle-finding algorithm from Abhinav's project, but we were not successful at fielding a fully capable player with it.
A destructive task is one aimed not at augmenting one's own score, but at preventing another player from gaining points. This can be achieved by looking for opponents' potential rectangles and sending a robot to interfere with that rectangle.
Destructive tasks differ from chasing strategies (where one robot attempts to pursue an opponent's robot) in that they are aimed at preventing specific opposing rectangles and not at opponents making lines in general. While strict chasing enables one to captialize on an opponents' work by building whatever shapes he builds, it is turn-consuming work.
Destructive tasks are based on the theory that while it is necessary to paint many boxes to complete a rectangle, one need cover only one box to prevent a rectangle. Furthermore, if one's opponent has a small number of robots working on the rectangle relative to the rectangle's perimiter, it is sufficient to move to disrupt the rectangle only occasionally to completely prevent the rectangle's completion. Thus, destroying enemy rectangles in a minimal way can be just as effective destructively as chasing, while freeing up valuable robot time to perform constructive tasks with the turns that are not spent following your opponent move-for-move.
Furthermore, a destructive-task approach is superior to chasing in that it can work in multiplayer games (since it only takes one robot to disrupte the work of potentially several opponent robots). It is also better in that there are some anti-chasing strategies that are fairly easy to implement -- usually involving the chased robot stopping or moving away. It would be harder to detect that a robot is attacking a rectangle, and there are also fewer recourses available. Probably the only response to a robot that is attacking the rectangle you're trying to make is to try to make a different rectangle, and even this leaves you vulnerable because as soon as you give up on the first rectangle in favor of the second, the attacking robot can start attacking the new rectangle.
We briefly explored the possibility of having each robot be an automaton that chose its direction based on the board conditions around it (specifically, in the 5x5 or 7x7 box around the robot).
In our exploration, we tried having the robot tend toward:
The idea behind this approach was that if we did a large number of tests on a large number of automata, we might find some that performed particularly well.
Unfortunately, we decided that this approach is probably too simplistic to yield useful results. The biggest problem is that it is most efficient to take into account the big picture and have robots work together. Such cooperation is not possible when robots are unaware of one another.
A future strategy might incorporate this approach as part of a bigger strategy. One modification that would probably be necessary is for each robot to take into account the entire board, and not just its own little piece.
The cavalry strategy, even in its blind form, is a relatively strong strategy that can carry its weight in both two- and multi-player games. Cavalry has most of the advantages of army (army is in fact a special case of the cavalry strategy), but is superior in that it yields significantly better PPRT than army when the spacing between robots is greater than 1.
The royal cavalry approach is better still, since it solves several of the cases where the blind cavalry player is weak.
This strategy would involve making the initial rectangle, and then sending all robots radially outward. When an enemy robot was about to come within destroying distance of one of the lines, that robot would turn inward to close off its rectangle.
Having a good algorithm for finding the best rectangles that are near one's robots would enable the optimal rectangle tracing algorithm to be highly useful.
To effectively destroy opponents' rectangles, one would need to implement an algorithm for finding these rectangles. This algorithm would likely take into account what lines opponents have already completed and what directions their robots are heading in. Then the nearest available robot would be sent to ruin that rectangle, and once the rectangle was sufficiently ruined, the robot would be free to do something else until the rectangle became a threat again.
In this way, if an opponent has several robots working on one rectangle, they can all be nullified by the work of one of your robots. If the opponent realizes what has happened and sends his robots off to do other tasks, your robot has done its job and is now free to do something else.