

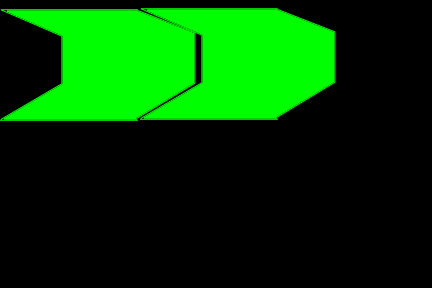
In the case shown, the placement in the second picture is shorter horizontally than in the first picture. If each shape had been placed optimally at each step, the best that could've been achieved is the first picture.
The second project, Cookie Cutter, was a game where a specified number of copies of polygonally shaped cookies were to be cut out from a piece of dough 1.0 units in width and infinitely long. The goal of the game was to use a combination of translation and rotation on the cookies so that the length of dough expended was as small as possible.
The Cookie Cutter problem has several interesting aspects that should be brought to light before discussing strategies. The first is a choice of a heuristic versus an overall algorithm for attacking the problem. A heuristic involves trying to minimize the amount of dough used with each additionally placed copy while an overall algorithm tries to examine the entire placement configuration, i.e. all copies included. The strength of a heuristic lies in the simplicity of applying it. Once the procedure for placing one cookie has been determined, for all other copies, simply apply the heuristic repeatedly until all copies have been placed. On the contrary, for an algorithm, all cookie positions must be examined together in order to figure out the best possible configuration, and at any point in the midst of the calculation, we cannot assume certain cookies have been set and will remain at their positions. Instead, all cookie positions must be considered with respect to all other cookie positions, and changes in one placement could lead to re-positioning of all other cookies. This can potentially cause performance issues as well since the algorithm might need to re-examine all cookie placements for each change in the placement of one cookie whereas the heuristic only needs to consider the placement of the one cookie with respect to those cookies that act as boundaries for it. This is especially the case when the number of copies to be placed is large.
The advantage of the algorithm over the heuristic is that the former could potentially find the optimal solution that the latter might not be able to. For example, if the optimal placement requires that one of the cookies is not placed to minimize the length of space occupied, i.e. not optimal for that particular cookie, so that additional cookies may be placed in combination with that copy to form the optimal overall placement, then a heuristic will not find that solution. The heuristic will always look for the optimal placement at each step, which precludes solutions that are non-optimal at certain steps along the way.
In the case shown, the placement in the second picture is shorter horizontally than in the first picture. If each shape had been placed optimally at each step, the best that could've been achieved is the first picture.
One possible solution that leverages the advantages of an overall algorithm while avoiding some of its pitfalls is to apply the algorithm at different levels. In order to limit the total number of possible configurations to explore to a manageable size, we could stipulate that only placement of n copies where n is within some reasonable limit, e.g. 20, would use the algorithm. For n greater than 20, we break up the cookies into groups of 20 or less cookies and apply the algorithm separately to each group and then combine them together. The combination step could use either a heuristic or an algorithm. The idea is that we treat the groups of 20 or less cookies as one whole and manipulate each of them as a single cookie making placement much less complex. In most cases, the combination step would involve simply pushing one group into the other as far as possible. One drawback of this solution is that it might not find the absolute optimal solution for all copies since it does not examine all copies with respect to each other. Thus, in essence this solution omits some small portions of the search space for a sizable gain in efficiency. The use of an efficient algorithm over an heuristic could also be considered a meta-strategy, a class of strategies we discuss in more detail below.
Speaking of efficiency, one aspect of the problem worth considering is whether or not a complex strategy is worth implementing. As we worked through this project, we noticed that some complex strategies required as much time as brute force searches did but took much longer to implement because of its complexity. In those cases, the question must be asked whether or not its worth it to go with the complex strategy. In computer science, where the three primary factors governing the measurement of efficiency - time, space, and cognitive strain - come into play, it would not be worth the added time and cognitive strain requirements to implement a high complexity algorithm over a brute force one, especially if it can be shown that the former has no clear advantage over the latter. However, if the algorithm does have some advantage, then it would probably be better to choose it over the brute force algorithm, which even though is much simpler and avoids issues like emergent properties of complex systems or excessive cognitive strain and development time, has the crucial flaw of lacking scalability.
Another aspect of the Cookie Cutter problem is that different classes of strategies seem to work better for different classes of cookie shapes. One class of strategies based on simulating real physical interactions between cookies as objects, which we will call physics strategies, seem to work quite well for convex shapes. But when dealing with concave shapes where a protrusion on the shape fits well with an indentation in another part of the shape, physics strategies seem to have trouble finding this fit. One situation that exemplifies this predicament is that if you randomly place jigsaw puzzle pieces on a flat surface and then compress them from all sides, it's very unlikely that the pieces will fall into a configuration of occupying minimal area. That can only be done by matching the pieces with the slots they are suppose to fit in deliberately. One the other hand, a strategy that matches sides of similar length and pairs of angles that add up to 360 degrees will be much better suited for dealing with cookies of the puzzle type. But this strategy will not perform as well as a physics strategy when placing convex shapes. A potential solution to this problem is to determine the type of the cookie before choosing the method to apply. However, determining cookie type is not necessarily trivial. One way around this is to simply run all the methods on the cookies and choose the one that performs the best. The only problem with this solution is that it is potentially very expensive in terms of computation time.
These are various strategies we brainstormed and analyzed and tried to implement. Due to time constraints, we weren't able to produce completed versions of all of them. Nevertheless, it was a valuable learning experience for us to have looked at various strategies and their respective strengths and weaknesses, and we have documented our finds below.
The rectangular method is conceptually one of the simplest methods. The idea is to find the bounding box of the cookie, and then pack these boxes together as tightly as possible. This is fairly easy to implement because of the ease with which we can work with boxes. Also, when we place two boxes next to each other at the same height, they naturally leave no empty space between them, so there's no need to check for holes. A weakness of the simple rectangular method is that a cookie, unless it is a box itself, leaves some part of the space in its bounding box unoccupied. When several bounding boxes are placed together, the holes created by adjacent bounding boxes can sometimes accommodate another cookie but is in fact wasted. Another problem of the rectangular method is determining at what orientation of the cookie should the bounding box be constructed. The first thought that comes to mind would be to minimize the length of the box in the horizontal direction. This would definitely result in the optimal placement of one cookie, and might be optimal overall. But in many cases, minimizing the vertical dimension of the bounding box over the horizontal means that more cookies will be able to fit in each vertical column and could result in a better overall placement. Then there is the idea of maximizing the percentage of space within the bounding box that is occupied by the cookie. The rationale for this is that minimizing the amount of wasted space per box can help minimize the amount of wasted space overall. Thus, it is not a simple problem to decide how to orient the cookie before specifying its bounding box.

Notice the space wasted in the vertical direction by not pushing the stars up past the boundaries of the bounding boxes.
The rotation method uses rotation as its primary tool for finding optimal placements. The naive rotation method simply rotates a cookie about its centroid and for each increment in the angle of rotation, try to pack the shape as far to the left as possible. The rotation that uses up the smallest length is the one chosen for that cookie. A more complicated rotation method is to bring two cookies within contact and then rotate about the point of contact until no further rotation can take place without overlap. At that point, another point of contact is used as the pivot to continue with further rotation. At each stable point, point in rotation where no further rotation is possible without selecting a different pivot, the length of the placement is recorded, and the stable point with minimal length is the chosen position for the cookie. The strength of the rotation method is that it has the possibility of finding tight fitting placements like two triangles combined into a parallelogram that a method like the rectangular method that uses translation alone would not be able to find. One seemingly trivial yet bothersome adjustment that needs to be made when rotating to find the best fit is that the epsilon needed to eliminate boundary overlap between cookies can sometimes prematurely terminate rotation because the shape is not being rotated precisely about vertices of contact. In any case, the rotation method by itself is by no means an optimal method. Rotation must be used in conjunction with translation to have any chance of yielding the optimal results.


In place rotation of a shape, i.e. about its centroid, to obtain a better placement.


Rotations about points of contact have the problem shown in the picture above. The rotation is ended by the collision of the shape with a boundary. The optimal solution would have been to also use translation to slide the shape into the slot.
The sampling method is one form of a brute force method. The idea of the sampling method is to rotate and/or translate a cookie by some increment, taking a "sample", and, for each sample, check for overlap with other cookies and determine if it is a placement with minimal length. If the increment used is large, a lot of potential placements will be skipped over. If the increment is small, there is a much better chance of finding a good placement, but the computation time needed will increase dramatically. The strength of the sampling method is that given a small enough increment, it could potentially find a very near optimal placement. Also, it is less complex than most other methods. Its weakness is the amount of calculations it needs to do. This problem can, however, be mitigated by tweaking the code to make various functions more efficient and eliminating certain ranges of values that don't need to be considered due to overlap. The sampling method by itself, without sufficient auxiliary algorithms to boost efficiency and lower running times, is not really a viable solution especially for a large number of cookie copies. It is much more useful as a tool to empirically find solutions to smaller sub-problems that are not solvable analytically using mathematics. This way its limited application within a larger more complex method minimizes its undesirable effect of time consumption while keeping it still useful as part of the encompassing method.
While working on increasing the efficiency of the sampling method, we asked ourselves how best to reduce the size of the search space. And one way we thought of was applying a divide and conquer algorithm on the search space. Essentially, we want to make our decisions based on a tree so that we can reduce the size of our search space logarithmically. For example, in the case of sampling, we can sample with big jumps, possibly sample only once or twice for each block of space that is the size of a bounding box. We can then sort our blocks by percentage of block area that was overlapping between cookies and eliminate those blocks that exceed a certain threshold percentage. Next, we do a search with a finer granularity starting with the block with the highest percentage of overlap or perhaps the leftmost block. This way, we can quickly eliminate large portions of our search space and spend more of our time searching in the right places. We never got to implementing this idea, but we feel that it has great potential, and that this train of thought can be applied to many other sub-problems, thus, it is worth mentioning.


The left is sampling rotations of a shape, while the right is sampling translations of the same shape.
The general concept of compaction is implicitly used in almost all the other methods since the goal of the game is to compact everything as much as possible. The specific compaction method that we came up with is based on the observation that the distance between two cookies, the maximum distance that they can be compressed before overlap occurs, is always the distance between some vertex of one of the shapes with a vertex or line of the other shape. This is a critical observation for us in that it lets us find precisely, at most, how much we can press one shape up against another. Simple application of this knowledge is to try various rotations of each cookie to determine where and how we can pack the cookie in the most. This is essentially using the compaction method together with some sampling. Like sampling, compaction is more useful in conjunction with other methods.

Depicted here is a simple compaction method whereby each shape fits itself where it can push itself as far to the left as possible.
The repulsion method uses the opposite idea of the compaction method. Instead of placing shapes in open space and then pressing them together, we place the shapes on top of each other and let them repel each other into an optimal placement. The repulsion method relies on the physics of forces and torques to guide the movement of the cookies. We calculate the magnitude of repulsion based on the area of overlap between two polygons. The advantage of the repulsion method over the compaction method or some variant of it is that there is the possibility of a cookie being pushed into an unoccupied region between other cookies that would not be reachable via compaction because the hole is closed off by cookies. One problem with the repulsion method is finding the initial placement that would lead to an optimal fit. Placement in the midst of already placed cookies might generate equilibrating forces that cause the cookie to reach a stable equilibrium within the sea of cookies that is not a possible placement due to overlap. Placement at the frontline of cookies will guarantee a viable placement, but might miss holes in the placed cookies that could be used. This method turned out to be the one we had the most difficulty implementing due to the complexity of various sub-problems involved.



The second shape is placed with a slight perturbation relative to the first shape causing the area of overlap between them to generate a force that pushes the second shape downward. The pictures show the shape sliding until there's no more overlap and the force vanishes.
This method looks for sides of matching lengths and/or angles of two cookies that add up to 360 degrees. The assumption behind the method is that certain classes of shapes have optimal tight packings that match same length sides, e.g. triangles, and angles that add up to 360 degrees, puzzle shapes. The strength of this method is that it is quite efficient in finding the right configurations for these classes of shapes since it starts assuming that it is looking for a specific type of solution. Its weakness is that if the given shape doesn't belong to one of these classes of shapes, then the configuration it arrives at doesn't necessarily have any notable advantage and is improbable of being the optimal solution.
From this picture, we can see that dimension matching can give a placement that maximizes the percentage of area occupied by cookies within a bounding box when used on cookies exhibiting puzzle piece properties.
This is one of the methods we thought of trying initially. After all, the problem of wasting minimal space when placing polygons seems to overlap significantly with the problem of finding and placing shapes to tesselate the plane. After further brainstorming, however, we came to the conclusion that this method is not viable because the dimensional limits of the dough that we are allowed to work on and the fact that the cookie shape and size are unrestricted means that we might not have the space needed to find and place tessellations. Only for cookies that are small relative to the dimensions of the dough would tessellation potentially be of use. In essence, tessellation is much like the rectangular method, but instead of using a bounding box, we can use any bounding shape that tessellates the plane. The same problem with the rectangular method, therefore, also applies here, i.e. we cannot easily determine whether or not the unoccupied space in the bounding shape can be used effectively in some other way.
This is a specialist, as opposed to a generalist, approach to the problem of finding optimal placement much like the dimension matching method. The idea is to determine some basic properties of the shape given, and then apply some optimizations specifically for those shapes. For example, if you determine that the shape is a triangle, you immediately know that you can combine them into a parallelogram and then regularly repeat the parallelogram. Similarly, if you determine that the shape is a quadrilateral with parallel sides, you can piece them together in a specific way also. Or if you figure out that the shape is a regular polygon that tessellates the plane, you can directly apply the tessellation configuration if it fits within the dough. Shape specific methods are very narrow in scope but can prove very effective on shapes that it anticipates correctly and knows how to deal with.
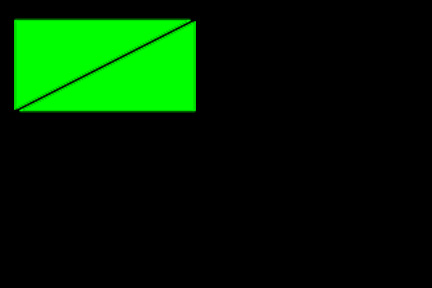
This example shows that if we determine that our shape is a right triangle, a simple task, then we can apply our knowledge that two of them in the right orientation, which we can calculate from the dimensions, form a rectangle, which is easy to place.
Hybrid strategies use a combination of the strategies we documented above. In reality, most complex strategies are hybrid strategies employing numerous strategies to conquer different sub-problems. Below, we elaborate on some of the hybrid strategies we devised and implemented. One note about hybrid strategies is that there are many ways to combine multiple strategies. Even the same two strategies can be hybridized in a variety of ways with differing levels of effectiveness.
In this method, we first rotate the shape to obtain an orientation with a minimum horizontal length. Next, we place our cookie copies in this orientation and compact them both vertically and horizontally. The method is fairly effective at finding good placements of large concave shapes. The next step of improvement in the evolution of this method is to find best fitting rotations individually for each of the cookie copies instead of locking all copies into a single orientation. One advantage of this method is that it is fast. The algorithm itself is not overly complex, therefore, it finds an acceptable configuration with blazing speed compared with other methods.
This method uses the compaction method to bring two shapes into contact and then switches to the rotation method to pivot about the point of contact to look for further compression. The next step in this algorithm is to add translation. That is, after we have to obtained the best placement from compacting and rotating, we use vertical translation to see if we can one, minimize the vertical length and two, create room for further compaction. The method we actually implemented differs slightly from this in that the rotation step is done in place instead of about a point of contact, and we alternate between rotation and compaction stages as long as there is distance gain at each step. The property we were hoping to see is the ability of the cookie to try and squeeze its way into bounded spaces.
There was a flaw in the adjustment of the vertical position of the shapes in our algorithm, but notice how the combination of compaction and rotation is able to find the gap and try to use it.
This method uses a combination of sampling and compaction. It's basic idea was mentioned above in the description of compaction. We obtain an array of samples of a cookie rotated and translated at regular intervals. For each sample, we determine how much we can compact it to the left. Then we select the position that yields the greatest compaction and then apply the compaction. There's also an aspect of vertical translation in this method in that we also translate the shape vertically at regular intervals and test for leftward compaction at those points also. If we don't, then all of our shapes will end up being placed on top of each other resulting in a horizontal stack.
We felt that a variant of the rectangular method that uses compaction and rotation would be the best method for finding near optimal placements for non-puzzle piece cookie shapes. Since dimension matching has the most potential for handling puzzle shapes, we decided to combine the two to complement each other. In order to determine when to apply which method, we had to come up with a way of recognizing puzzle shapes. The algorithm we devised was very similar to our dimension matching algorithm, so we decided instead of running the shape recognizer, and then running one of two methods, we would just run both methods and select the one that yielded the better placement. Some flaws in our dimension matching method prevented us from completing this combination.
Note: A concluding remark we want to make about hybridizing strategies is that the simplest way to combine any number of strategies is to run them all and select the best placement. However, this is not truly combining methods since each method is applied on the entire set of cookie copies. Each method is not applied to individual copies where appropriate to achieve a best overall placement.
Some strategies we came upon apply on a higher level than the detailed strategies enumerated above. These meta-strategies can be applied to any regular strategies to increase effectiveness and therefore are just as important if not more so.
Multiple cookie manipulation means translating or rotating a number of cookies as a group. The advantage of multiple cookie manipulations is that once you have found the optimal placement for a group of cookies relative to each other, you can manipulate them as a single object so as not to disturb their positions but at the same time have the versatility of being able to relocate them with respect to other cookies for a potentially even better placement. For example, once two triangles have been locked together into a parallelogram, you can then rotate this parallelogram to obtain the orientation with the minimum horizontal length. This is something not so easy to achieve had the two triangles been placed independently of each other, the reason being that in order for the two of them to be in optimal placement, the first triangle might need to be in a non-optimal placement by itself prior to placing the second triangle.

This is a good solution that optimizing each shape individually without considering position relative to the other shape would attain. This is not to say that the configuration below cannot be achieved by manipulating only one shape at a time. Here, we're only showing a simple example, but with increased complexity of shapes, manipulating cookies singly will have an increasingly harder time finding the best placement.


If we consider the two placed triangles as one shape, we can obtain a new optimal placement by rotating them together.
While playing around with various strategies, we observed that physics based strategies like compaction and rotation all share a common weakness. They're all incapable of finding certain optimal orientations. The problem lies in the way they detect limits. Physics methods stop rotation or translation when cookies come into contact with each other. The assumption behind these methods is that points of contact are good limits for stopping searches even though there are situations in which this is not true.


If we use a physics model to govern our motions and try to compact the shapes by translation, we would reach the stage shown in the first picture. Even with rotation, we have problems getting the best that we can.


The picture on the left shows what our physics model stops us from finding but is in fact a better placement. You might say that with rotation and translation and a physics model, you can get the placement in the picture on the right, which is optimal also. But if you consider the epsilon needed, then it is not as good as the one on the left. Also, in general, physics models do not allow us to explore holes locked in by other cookies, which are further left than anything we can find on the cookie frontline.
One alternative to the point of contact model for deciding when to stop searching is to use a measure of percentage of area occupation of a block of dough in conjunction with a threshold to decide whether or not to keep searching in some space. Also, once an optimal placement for some cookie shapes are found, its percentage of area occupation can be used to measure the level of optimality of future placements. Whatever the search limit chosen, the lesson here is that attention should be paid to the parts of the search space that the limit explores because it can be even more important than the strategy that it is a part of.
The final submission of our player consisted of three players combined, a rectangular/rotation/compaction player, a more efficient version of a pure sampling player, and a compaction/sampling player. Some of our other players were omitted due to bugs and excessive computation time of combining all methods.
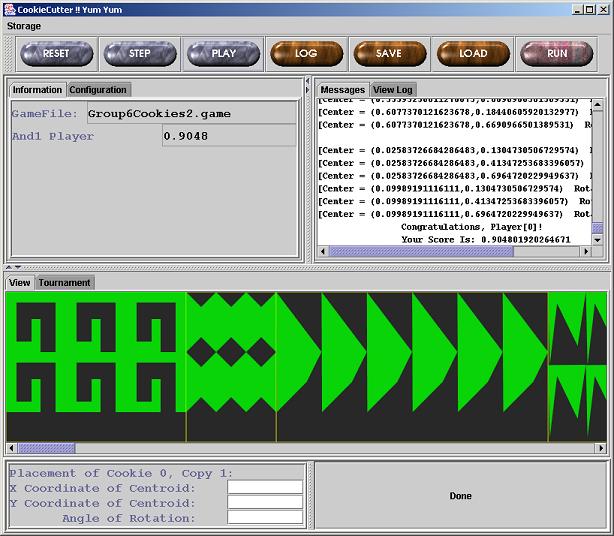
We tallied the rankings of our player in all games played in the tournament and reorganized it into a matrix in order to facilitate identifying relationships between the various types of cookies played and the strengths and weaknesses of our player. The chart is separated and color coded into three sections based on the source of the cookie shapes. Each box contains our ranking for the tournament round using the shape specified at the left and the number of copies indicated at the top. The average ranking over all different copies of the same shape is calculated and shown at the right. The overall average ranking is displayed at the bottom right. The results are also sorted by average rankings.
[1]
Ā:
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Our player seems to have performed best when placing the extremely large L-shaped cookie and the extremely small cookie. Closer inspection of the small cookie case reveals that a bug in our player caused our cookie placement to be invalid for some of the rounds, and that we could've performed much better for that cookie otherwise. It's not apparent from the data why we performed much better for shapes of extreme sizes. We surmise that the other players probably spent a large amount of time optimizing for the typical shapes and devised algorithms that perform well when searching various orientations given enough freedom to move but have a more difficult time with oversized shapes that have very limited ranges of movements and combination possibilities. Aside from those observations, we note that our player consistently ranks in the exact middle of the pack, averaging an overall rank of 4 out of 7 players.
In comparison with project one, this project was definitely different in its focus. Our analyses and approaches were much more heavily mathematically based. Also, the set of potentially good solutions seemed at first very limited, but as we delved into the project, we discovered there were many layers to the problem, and it had a hidden complexity that was not at all trivial. We tried to mine the complexity of the problem and use it to our advantage through implementing various intuitive and counter-intuitive algorithms. However, the more we did so, the more we realized that we have to look past the complexity and explore the problem from a higher level of abstraction to make considerable progress. That's when we moved from developing and testing strategies to categorizing strategies by similarities, identifying common strengths and weaknesses, and formulating meta-strategies. Time constraints limited us from going further down that path, but we feel that it is an important conclusion that perhaps future groups might find useful.
While working on this project, we spent the majority of our time coming up with and implementing solutions to sub-problems, most of them mathematical in nature. It would, therefore, probably benefit future groups working on this particular problem, if it's to be ever used again, to have access to a larger library of functions for manipulating cookies and performing various calculations on them. Most of these can probably be found in people's code submissions. If groups are given more tools to work with, they could focus more on exploring various strategies.