Strategies
This game has several different aspects to it that require consideration. The primary strategic aspect is information tracking, that is representing and interpreting the information we gather about other players' cards and the hidden cards through observing their moves. This is what helps us win and is primarily offensive in nature. In addition to this, we need to carefully think about how we ourselves should move, i.e. who to interrogate, what cards to ask about, and what to reveal when questioned. These are auxiliary strategies both offensive and defense in nature in that they help us to extract information more efficiently while hindering the progress of our opponents. Below, we have separated the strategies into two categories based on what we've just described, the primary strategies and the auxiliary strategies. For all of our discussions, we use the following symbols:
- N - the total number of cards
- k - the number of cards per player
- h - the number of hidden cards
- p - the number of players
Primary Strategies
Core Player
Card Weighting
Conditionals
History Mining
The Core Player is the base of all of our players. Each player must implement all aspects of the game including interrogation, answering, etc.. Many of the auxiliary aspects like how to answer can be the same for players with different primary offensive strategies. To avoid redundant coding, we implemented a complete player using the most fundamental strategies for all aspects. For our primary strategy, we used a simple heuristic. We interrogate players in sequence one after the other. In each interrogation, we ask about all the cards that we are not sure about with regard to that player, i.e. we do not know for certain if this player has or doesn't have these cards. This method of interrogation guarantees that we gain information about at least one unknown card every round. This guarantees us an upper bound on the number of rounds it takes us to have certain information about all the cards and be able to make a correct guess. That number is (N-k-h)*p. It's relatively simple to enhance this strategy by padding our interrogation lists with cards we know for certain do not belong to the interrogatee in order to confuse the other players. Subsequent versions of the core player have this improvement. To keep track of what we know, we use a list to represent what we think is hidden. Ultimately, the hidden cards are what we're interested in, so this is the most straightforward way to find out what they are. If we find out that a card belongs to some player, we mark it as definitely not a hidden. When the number of cards we have left unmarked equals the number of hidden cards, then we know those are the hidden cards, so we guess. This strategy will always give a correct guess if given enough rounds. As for answering interrogations, we simply select the first card from our hand that matches one of the asked for cards to show the interrogator.
After considerable thought and experimentation on how to use a matrix to represent the probabilities of each player having each card, we concluded that imposing the requirements of probability density functions on the probabilities of the cards has several weaknesses. One, it does not track conditional information, and two, it sometimes produces false inferences because of the simplifying assumptions made when calculating the probabilities. One way we tried to get around this is to use weights instead of probabilities. For each player, we keep a list of weights for all possible cards. When we are sure that that player has a card, the weight of that card becomes positive infinity. When we are sure that that player does not have some card, the weight of that card becomes negative infinity. For every negative interrogation response we observe, we set the weights of all interrogated cards to negative infinity. For every positive interrogation response, we add a small amount to the weight of all cards that were asked since we don't know which is the revealed card. The motivation behind this is that if A tells B it has some card in 1, 2, and 3, and A tells C it has some card in 1, 2, and 4, then we want to capture the idea that there's possibly a higher probability that A has 1 or 2. With that information, we can choose to guess before we have full knowledge of the cards. A safer alternative is to interrogate based on what we deduce a player probably has from the cards that are weighted highest for that player.
Regarding the weights, initially we used uniform weights, i.e. we added 1 to the weight value each time regardless of the number of cards in the asked list. To make the sums converge for large games and to account for the fact that the probability of the cards in a group of cards belonging to a player is less if that group is larger, we switched to geometric weights inversely proportional to the number of cards in the asked list. For example, if A responds positively to a list of three cards, then the weight of each card in our weight matrix is increased by 1/3.
The weakness of the weight method is that, though it seems likely, its not necessarily the case that A has a card in 1 or 2 in the example in the first paragraph. It could be that A has the 3 and the 4. The fact that 1 and 2 were asked for again could signify that other players either do not know if A has 1 or 2 or know for certain that A does not have 1 and 2. This is based on the crucially important deduction that players will not ask a player about a card that they know for certain belong to that player for fear that they might waste a turn if they're shown that card again. In that sense, it might be better to weight 1 or 2 less than the 3 and the 4. Based on this reasoning, we also implemented a version of the weighted player that uses inverse weights, meaning that we consider the cards weighted less to be the cards that are more likely to be owned by a player.
We tested the weighted player against various other players as well as our own core player. The weighted player guesses correctly before the core player a majority of the time. We can, thus, conclude that the weighted player has noticeable advantage over the basic player. However, this advantage is small because the difference in guessing time between the weighted player and the core player is small leading us to conclude that our assumptions about the weighted player are not very accurate. We also had the same results with our geometrically weighted and our inversely weighted players. Some of this diminished effectiveness might also be attributed to the fact that placement of the players and the number of cards in play greatly affect the outcome of the game. However, we were of the belief that we can do significantly better.
One problem with the weight matrix is that weighting, like a probability matrix, also does not preserve conditionals. A lot could be deduced from conditionals when they are combined together that is not immediately apparent by examining weight matrices. The problem is coming up with an efficient way of representing conditional information and combining them to derive more information. After some deliberation, we chose the simpler brute force method of maintaining all of our conditionals in a list. We created a class of objects called conditionals. Since each conditional is derived from the response to an interrogation, we chose to store it in the format that it's given to us. A conditional has a player, a card list, and a boolean response variable. The card list is the list of cards asked to the player, and the response is the player's answer. We keep a list of conditionals for all interrogations that have gone on. At the same time, we also keep lists like those in the weighted player that indicate which player has which cards or doesn't have hich cards for certain. In our list of conditionals, we do not keep singletons, conditionals where the card list has size one. Singletons are updated into our player-card lists whenever we encounter them. The key to conditionals is the combination of multiple conditionals. Our conditional class has combination functions for merging various types of conditionals with each other. For example, combining a conditional for A has 1, 2, or 3 and A doesn't have 2, 3, and 4 produces the singleton A has 1. There are quite a few different combinations of conditionals, and we tried to implement as many as we had time for. In our player, every time it's our turn, we obtain all the conditionals that appeared since our last turn, and then combine each one with everything in our current conditional list, which we have maintained since the start of the game. All singletons are reflected in the player-card lists and then discarded. All other newly produced conditionals are appended to our conditional list. This is the key step in that we try to deduce as much as we can from everything we've seen so far. We also check all our conditionals against our player-card lists to guarantee consistency and make sure our singletons are also used in combining conditionals.
The weakness of the conditional list is that it is immensely resource intensive. If we wanted to be thorough with our conditional merging, we would need to combine our new conditionals with all old ones. Combine the newly produced list with all old ones again, and repeat until we no longer produce any unique new conditionals. This is a process that can take a lot of computation time and memory. Also, we have only considered the combination of two conditionals. There are also multiple conditional combinations. For example, if A has 1, 2, or 3 and B has one in those three and so does C, then those three conditionals together can negate the cards 1, 2, and 3 in the hidden list. This situation could happen with more than three cards and three players as well, and therefore would involve more than three conditionals. Trying to combine all combinations of three conditionals from our list would require even more time than combining all combinations of just two. The problem has to do with selecting a combination of 3 items out of a list of n items. Lets say we're only dealing with 20 conditionals. That would mean we have to check (20 C 3) = 1140 different combinations. For real game situations involving more than two players, the game usually needs at least 60+ rounds. Since each round produces a conditional, we would have to check (60 C 3) = 34220 combinations. That's not accounting for all the conditionals produced in between and re-inserted into the list. Even with just two and three conditionals, there's this much computation, so combining more than three conditionals is not at all feasible. But that leaves out some important information that could advance our position significantly.
In our test runs with the conditional player, it performed about on par with the weighted player, not doing much better or worse. We attribute this to the fact that we limited how many levels of conditional combining we did. Initially we had set a much looser limit on how much combining we allowed. But we kept encountering "Out of Memory" errors, so we had to cap the combination step. After much consideration, we concluded that we couldn't overcome the resource problem of using the conditional player to its full capacity without coming up with a much more efficient representation of conditionals. Thus, we moved on to other alternatives for boosting the effectiveness of our player.
Both the weighted player and the conditional player translated player moves into a different representation and updated that representation with each round in trying to reveal information about the cards that would otherwise not be apparent. We thought, instead of maintaining our own representation along side the history of moves, why not just examine the history of moves when we think we're ready to guess? Our reasoning is that in reality all of the information revealed by the moves is present in the move history. We just need to find ways to mine the history data to extract that information. So we turned to statistical analysis of the move history. The key idea that we used in our history mining is that a player will not ask another player about a card that the former already knows that the latter has in order to avoid wasting a turn since no new information is revealed if the interrogatee answers with that specific card. From this, we can deduce that the cards that will be asked about the most are the hidden cards, which others have mentioned in class, because a player has to ascertain that every player doesn't have that card in order to know it's hidden whereas he/she only has to ask the player that has it to know that it isn't hidden. Based on this deduction, we simply tallied the number of times each card was asked and selected the h most asked about cards as our guess. To our amazement, this method was surprisingly accurate. Not only that, we were able to guess correctly much further in advance than any other player. We estimated when we should guess by taking the upper bound calculated in the core player and multiplying it be a fractional factor between 0 and 1. The smaller the factor the earlier we guess. Of course, the earlier we guess, the less information we have and the less accurate we are likely to be. This did indeed prove to be the case. Even so, there were times we were able to guess correctly over 70% of the time with a factor of 1/2. That is if a game needs 200 rounds for the basic player to guess correctly, we could guess correctly with only 100 rounds. In our tests with the last player submissions of the other groups before the tournament, we guessed correctly at 100 rounds in a 200 round game while all the other players needed at least 170 rounds to guess. Thus, we beat them by about 70 rounds!
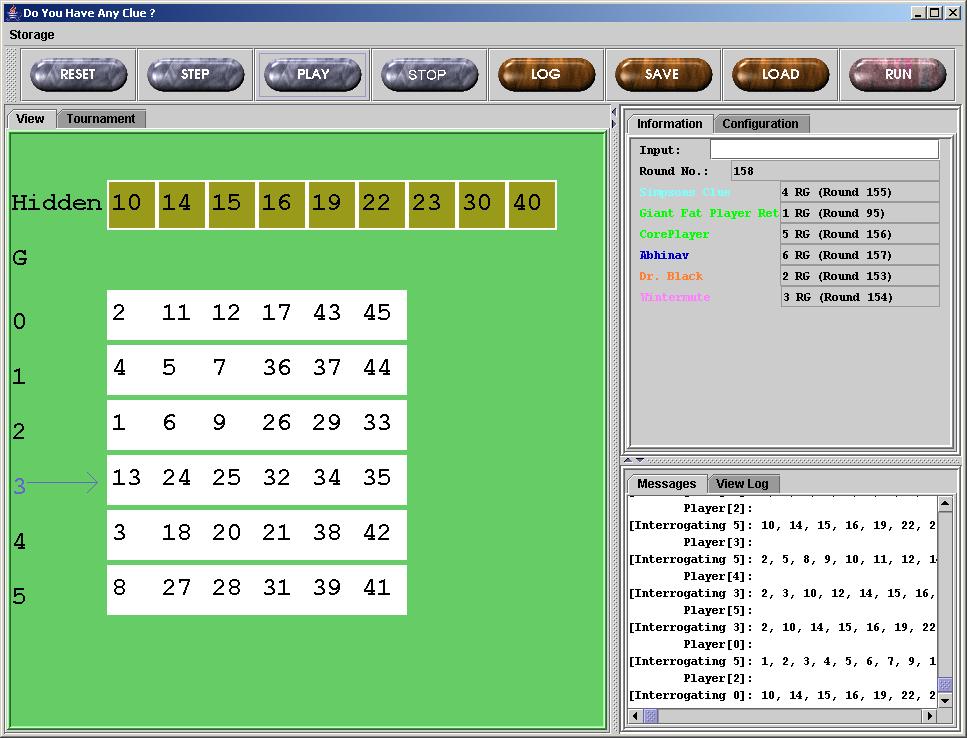
Here's a test run of our player guessing early against other players. Some players have been omitted due to exceptions and infinite loops and compilation errors.
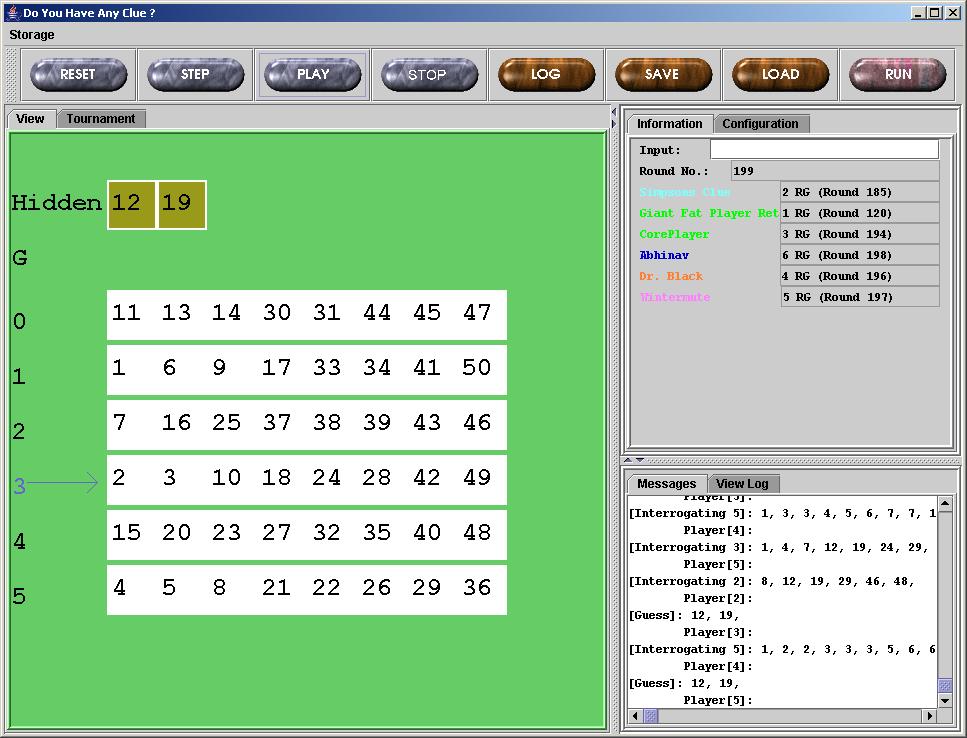
This is another test run. We guessed 65 rounds ahead of the 2nd guesser and got it right, too. Must be our lucky day.
As effective as history mining seemed to be, it was not without its faults. Our statistical player did guess wrong 30% of the time, and guessing wrong before everyone hurts our ranking severely since we become last making our player a "do or die" type. We increased the guessing factor to 2/3 to try to alleviate some of this, but it was only partially effective. In extensive tests, we discovered that, the success rate of our player was extremely sensitive to the placement of the players despite having a randomly chosen starter. We weren't sure why this is so, but for some player placements, our correct guess percentage was as low as 10%. Another important factor, related to the one just mentioned, is which players are participating in the game. Our statistical player does particularly well against some players and quite badly against others. We attribute this to the interrogation behavior of the other players. We assumed that they would ask about hidden cards the most, but there are ways to not ask about hidden cards the most and still not waste turns. This can be achieved by randomly choosing cards a player knows belongs to some other player to pad an interrogation with. Finally, the number of players and cards in the game also affected our performance. This we expected since the larger the game size, the more data there is to mine, so the more accurate our guesses are.
Another idea we tried, also derived from the same assumption about interrogations as the previous idea, is that since players won't ask about the cards they know already, we can deduce that the cards a player has been asked least about are the ones that that player has. To our disappointment, this was not the case. We explain this by pointing out that each interrogation only reveals one card, so the other cards, even though they might belong to the interrogatee, are asked repeatedly until they are revealed. Also, if the interrogator doesn't use all other cards to pad the list, but randomly chooses a subset, then some of those cards will have been asked as few times as the cards the interrogatee has. Of course, there's the case where a card is never asked because its place is already known at the start of the game, but we exclude those cards that are not even asked once from our searches.
Auxiliary Strategies
These are strategies that help our player be more efficient in gathering information or hinds the opponents' progress. The strategies used are fairly fundamental and are probably used by most other players in class. Nevertheless, it's important to mention them.
Player Interrogation
We interrogate players essentially in sequence. The only condition we add is that we check how much we know about a player. If in our deductions, we come to know all the cards of a player, we skip to the next player, and continue this way until we find a player who we do not know everything about. This is to guarantee equal speed of information gathering about all opponents. That way, we avoid the case where other people's interrogations provide us no information if we already know everything about the player that is being interrogated.
Interrogation Card Selection
We always ask about the entire list of cards we do not know for certain with regard to the chosen interrogatee padded with all the cards we do know for certain do not belong to this player. This serves two purposes. One, it minimizes the amount of information players who rely on probability matrices and conditional lists receive. Two, it helps our history mining player in making sure that the hidden cards are asked more than the non-hidden cards at least by ourself. This helps remove some of the statistical noise that players who randomly choose cards for padding create for us. To further increase the noise reduction effect, we ask for each card in our interrogation list multiple times in our history mining player.
Answering Interrogations
For this, we kept a list of what we have shown to each player. If any player asks us for a card we've already shown to that player, we show it again.
Group 2 Player
The submitted Group2PlayerEL actually had a combination of elements from each of the players described above. It used player-card lists to keep track of what each player definitely has and doesn't have. It keeps a list of conditionals updated with each turn to try to infer as much as possible from the other players' moves. It uses the history mining strategy with a factor of 2/3 for guessing. When the player is ready to guess, it will mine the history for the guess list, and then run it through the list of conditionals and the player-card lists to make sure that everything is consistent and no card that we know is not hidden is being submitted as a guess. After all verifications and substitutions are done, the guess list is submitted.
Tournament Results Analysis
In a few of the tournaments, the player ran out of memory due to the combination step of the conditionals. The same problem occurred when we did test runs. But we reduced the combination step until there weren't any memory errors on our tests. However, since the machines used in the tournaments differ from our test machines, we didn't foresee that the problem would show up again.
The average rank of Group2PlayerEL is not very high in general. However, this belies its performance. With respect to Group2PlayerEL, there are several important aspects to consider. First is that it is an aggressive guesser. It does not wait for full information to make its guesses, and because of the estimated round to guess, it is always first to guess. This alone merits acknowledgement since the first guesser has less information than everyone else and risks the most as was mentioned in class. Upon guessing, it either guesses correctly and takes first place, or guesses incorrectly and takes last place. The average rank is lowered by the frequency of last places despite many first place appearances.
A better measure of the player's performance is its ranking based on the number of times it came in first. As anticipated, in the smaller 2 and 3 player games, it performed poorly because of insufficient data to mine. In the 5 player games, its effectiveness begins to show itself. It was 1st once, and 2nd and 3rd for a good portion of the other games. In the 7 player games, it was almost always in the top 3. In the 7 player 2 and 3 card games it was 1st two out of three times. It performed best in the 9 player games, despite memory problems. It's consistently 1st or 2nd in the smaller 9 player games. And then its most decisive win is in the 9 player 8 card games where it wins 1st 663 times, which is more than three times the number of 1st places the next player had. One noticeable phenomenon is that it performs worse as the number of hidden cards increases. This is expected since there's a greater probability of having a wrong guess if there are more cards to guess. Here's a re-organized tabulation of some of the tournament results to illustrate our point.
Group 2 Tournament Results
A measure of effectiveness that is left out of the tournament results is the number of rounds our player guessed ahead of the second guesser. In our own test runs, we were able to guess as much as 70 rounds ahead of the next guesser. This large difference in guessing time is a clear sign that our player has a significant round advantage over all other players. Many of the other groups felt it safer to wait to guess so that in the worst case they rank above all the wrong guesses in the middle of the pack. However, we chose a high risk player because we felt it would be more rewarding when we did guess right so far ahead of the other players and more exciting to be riskier.