The chatbot has made waves over the past couple of months for being able to answer queries in a conversational tone. CS professors discuss what it can and cannot do correctly.
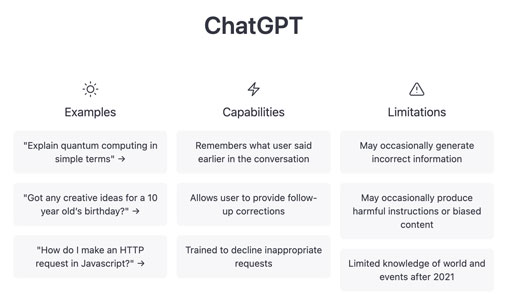
OpenAI’s ChatGPT is an artificial intelligence (AI) chatbot that is trained to follow the instruction in a prompt and give a detailed response. It is built upon GPT-3, a type of large language model (LLM) that predicts and generates text. Given a sequence of words, it will predict the word that has the highest probability of following next (kind of like autocomplete). These models are trained on huge datasets that allow them to generate answers to questions. ChatGPT works quickly and gives answers within seconds, and it also learns from every interaction and improves daily.
It can create a letter to your super asking for a repair to be done, write code and fix bugs, and suggest plot summaries for novels. But that does not mean that it is perfect. The problem with LLMs is that they can “hallucinate” and make things up. ChatGPT is guilty of this; some of the answers in its outputs do not even exist. It is also not trained to be truthful and it answers queries with a lot of confidence and authority, which is worrisome.
It is being compared to the last great tech disruption–the internet’s onset in the 1990s. We asked CS professors what the technology could do and how to use the tool the right way.
The original interface was cumbersome and needed an analyst who could use specialized programming languages to access the answer.
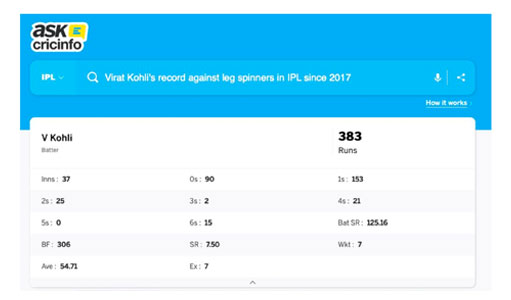
We developed AskCricInfo, which takes human input–questions or search queries–and converts the queries into a structured language like SQL that machines understand. The technology can “translate” the question into a programming language, find the answer, and quickly send it back to the user.
It is an excellent example of the power of underlying technology and what the tool can do. ChatGPT is very interesting. It is the first chatbot that makes “intelligent” and engaging conversations. There are definite use cases for making it a very effective teaching tool. It is up to the instructors to imagine a world where something like ChatGPT will always be available and teach students how to use it effectively. A lot can go wrong with ChatGPT- primarily because of its design that makes it bullshit confidently. But that is a problem with all LLMs, not just ChatGPT.
Kathy McKeown ChatGPT and the technology it is built on, GPT3, are game changers. With them and the other large language models that have recently emerged, models can now produce extremely fluent text. They are also able to perform a variety of tasks in a way that was not previously possible. And there are many situations in which they can be used to help us do things that we previously found tedious. But they are not able to do as much as we might initially have imagined. They have limitations that are not always immediately obvious, and researchers are taking the time to study them so that we can accurately characterize what they can and cannot do. Nonetheless, they change how we do research in the natural language field and how we build new models to carry out other tasks.
I think we need to learn how to incorporate them into our teaching because they are here to stay. Students know about them and will know how to use them. We will need to think creatively about how to teach students what these tools do well and what they do poorly, when they can be used as a tool to aid in research, and situations in which it would be dishonest. I imagine situations where we ask ChatGPT to answer an essay question, ask the student to critique the essay and identify what it does poorly, and then ask the student to write an essay that goes beyond what ChatGPT can do.
The worst problem with ChatGPT is that it is not always truthful. In fact, it may often lie or hallucinate facts. It does this very fluently, making its lies sound very plausible. This is quite a barrier to use in a real-world situation unless it is used by someone who knows what is correct, what is not, and can sift the good from the bad. Technology constantly changes, though, and it is a problem that researchers are actively working on.
Itsik Pe’er I asked ChatGPT about AI language models, and this is the output:
AI language models like ChatGPT, its competitors and successors represent a significant advancement in the field of Natural Language Processing (NLP). These models have the ability to generate human-like text based on a massive amount of input data, making them useful for various applications such as chatbots, question-answering systems, and content generation.
However, it is important to note that despite their sophisticated capabilities, they still have limitations and may generate outputs that are inaccurate, biased, or inappropriate. It is crucial to ensure responsible development and deployment of these models to maximize their benefits while minimizing potential harm.
The above demonstrates my thoughts more than I could otherwise express. In particular: it is already useful, but often not out-of-the-box, but I am a techno-optimist and believe even more usefulness is coming.
As a former judge in high school debate competitions, it reminds me of the most eloquent contestants, who would, if they needed to, lie through their teeth without missing a heartbeat. For instance, in response to this prompt, “What could go wrong with tools like ChatGPT?”, it writes:
There are several potential risks associated with the use of AI language models like ChatGPT: Bias: AI models are trained on large amounts of text data, which may reflect societal biases and lead to biased outputs. Misinformation: AI models may generate false or misleading information, which could have serious consequences if relied upon. Privacy Concerns: AI models process large amounts of personal information, raising privacy and security concerns. Misuse: AI models may be used for malicious purposes, such as spreading hate speech, fake news, or conducting phishing attacks. Job Loss: AI models may automate certain tasks, leading to job loss in industries that rely on those tasks. Therefore, it is important to carefully consider the potential risks and consequences of AI models and to develop and deploy them responsibly to minimize potential harm.
These are all valid points, but more context needs to be considered:
When it comes to bias, chatbots are worse than the best other (human?) alternatives but much better than the median ones.
Misinformation is a big problem when compounded by misuse, and we can see that happening now with stories posted online.
Privacy concerns depend on who has access to the data in ChatGPT and what can be done with it. But given that we all carry powerful tracking and sensing devices 24/7, our privacy is already weakly protected against powerful actors.
Some attention-seeking blogs and websites overstate the job loss point. Many jobs will become more efficient; many jobs will change; many jobs will be created, and, yes, many will be lost. People will adapt, and we will all be better for it.
PhD student Tuhin Chakrabarty talks about how his research is tapping into the creative side of computer science.
The field of natural language processing (NLP) has ramped up by leaps and bounds. This branch of artificial intelligence focuses on the ability of computers to understand and process language as humans do. It has been in the news these past few months because of a chatbot, ChatGPT, that can provide answers and data conversationally. The technology gives us a taste of just how powerful and useful NLP can be.
Tuhin Chakrabarty wants to see how much further he can push NLP in the field of computational creativity to see how computers can generate creative output. This is what ChatGPT had to say about computational creativity:
Computational creativity is a field that uses computational methods to simulate and enhance human-like creativity, producing valuable outputs such as art, music, stories, and scientific discoveries. It aims to understand and replicate the cognitive processes involved in human creativity, combining techniques from AI, cognitive psychology, and philosophy. Examples of computational creativity include generative art and music, game design, natural language processing, and scientific discovery. Ultimately, computational creativity seeks to leverage computers and algorithms to augment and extend human creativity, creating new possibilities for creative expression and innovation.
Tuhin Chakrabarty
“Generating text beyond a few sentences was almost very difficult two years ago, but things look much better now. It is not perfect, but I am optimistic,” said Tuhin Chakrabarty, who first became interested in computational creativity in 2019. “One of the things that I am excited about is how better we can align models like ChatGPT to human expectations and different cultures.”
Instead of creating text conversationally, Chakrabarty’s research focuses on how AI can be used to create metaphors and detect sarcasm with little to no training data. The fifth-year PhD student advised by Smaranda Muresan has expanded his work to generating long narratives of 2,000-word documents and visual metaphors. We recently sat down with him to learn more about his research and the creative possibilities of NLP.
Q: You mentioned that you became interested in doing research during your MS. What happened that made you interested in doing research?
I did not have much research experience as an undergrad. I got accepted to the CS masters program and I was fortunate enough to take a class offered by my advisor Smaranda Muresan, which still happens to be one of my all-time favorite courses at Columbia. Computational models of Social Meaning was a graduate seminar course about impactful papers in NLP. Reading all the papers in that class made me think about what I want to do with NLP and how so many interesting research questions can be answered computationally by studying language. Alongside this, I was also working with my advisor and my friend Chris Hidey on extracting arguments from social media. That experience was really precious. The enthusiasm everyone shared in trying to solve the problem at hand made me sure of my decision to pursue research.
Q: How did you become interested in computational creativity? And what is it?
Around 2019, Nanyun Peng and He He, two very important researchers in the field of computational creativity, wrote a paper on generating puns. I happened to attend NAACL 2019 in Minneapolis, where the paper was presented. I thought the paper was beautiful in every possible way and it quantified the surprisal theory in humor algorithmically. This made me really fascinated about how we can use inductive biases to help machines generate creative output. For selfish reasons, I reached out to Nanyun Peng and told her that I wanted to work with her. She was very kind and agreed to mentor me. My PhD advisor Smaranda Muresan is one of the experts in the field of Figurative Language, which deals with creativity. So, of course, that influenced my decision to work in computational creativity too. Computational creativity is a multidisciplinary endeavor located at the intersection of artificial intelligence, cognitive psychology, philosophy, and the arts. The goal of computational creativity is to model, simulate or replicate creativity using a computer to achieve one of several ends:
To construct a program or computer capable of human-level creativity.
To better understand human creativity and formulate an algorithmic perspective on human creative behavior.
To design programs that can enhance human creativity without necessarily being creative themselves.
Q: How can you train a model or algorithm to interpret creativity or language?
State-of-the-art models are often found to be inadequate for creative tasks. The principal reason for this is that in addition to composing grammatical and fluent sentences to articulate given content, these tasks usually require extensive world and common sense knowledge.
It should also be noted that current approaches to text generation require lots of training data for supervision. However, most existing corpus for creative forms of text is limited in size. Even if such a corpus existed, learning the distribution of existing data and sampling from it is unlikely to lead to truly novel, creative output.
So we have to rely on unsupervised or weakly supervised techniques to train an end-to-end model to interpret or generate creative text. Of course, with the advent of Large Language Models and few-shot learning, we can now prompt a model with a few examples of creative text and it can somewhat generalize (but not as well as humans). My dissertation deals with a lot of this.
Q: Let’s talk about your work with the New York Times. What type of research questions did you have to answer while there? How was it different from what you have been doing?
Over the past several years, a key focus for NYTimes Research and Development has understood how advances in machine learning can extend the capabilities of journalists and unlock reader experiences that aren’t possible today. Questions and answers are central to how humans learn. Times journalism frequently uses FAQ and Q&A-style articles to help readers understand complex topics like the Covid-19 vaccines. To enhance this style of journalism, we experimented with large language models to match questions to answers, even if the reader asks their question in a novel way.
Last year we launched a new research effort to explore generating open-ended questions for news articles. Our hypothesis is that understanding the questions our news articles are implicitly answering may be helpful in the reporting process and may ultimately enable us to create FAQ and Q&A-style articles more efficiently.
This was fundamentally different from what I have been doing because I had to work towards upholding journalism values such as accuracy and verifiability. In creativity, your model can generate something that does not require attribution. But, when working on a project that deals with news and journalism, the focus is on factuality.
Q: One of your five research papers at EMNLP was from your time at the NY Times, right?
Recent work on question generation has primarily focused on factoid questions such as who, what, where, and when about basic facts. Generating open-ended why, how, what, etc., questions that require long-form answers has proven more difficult. To facilitate the generation of open-ended questions, we propose CONSISTENT, a new end-to-end system for generating open-ended questions that are answerable from and faithful to the input text. Using news articles as a trustworthy foundation for experimentation, we demonstrate our model’s strength over several baselines using both automatic and human-based evaluations. We contribute an evaluation dataset of expert-generated open-ended questions and discuss potential downstream applications for news media organizations.
Q: What are you working on now? What are the kinds of research questions that you hope to answer?
Much of my recent and upcoming work is on human-AI collaboration for creativity. I recently worked on developing methods and evaluation frameworks for two creative tasks–poetry generation and visual metaphor generation–by leveraging collaboration between expert humans and state-of-the-art generative models. I further highlighted how collaboration improves the final output over either standalone models or only humans.
I have long focused on developing and evaluating machine learning models aimed at creativity in an isolated setting. This somehow limits their capacity to behave in an interactive setting with real humans. In a creative setting, it is crucial for models to understand human needs and provide assistance to augment human capabilities and improve performance based on human edits or feedback over time. So that is my focus now.
Q: About doing a PhD, what are the things you wished you knew before starting it?
This is a difficult question. Pursuing a PhD can be a really fun experience, but at the same time, it can be daunting. There is a lot of uncertainty around research questions and whether something will work or not. I wish I had been a little easier on myself and not taken everything personally. Like, if an idea didn’t work, instead of spending months trying to make it work, it is okay to give up and move in a different direction.
Q: What are your tips for people who want to pursue a PhD?
One of the things I learned during my PhD is to focus on what you care about. There are hundreds of researchers who might work on slightly dense areas, while your work can feel niche. This is not a problem. When I started working on NLP and creativity, the field still felt very young, but over the past three to four years, it has grown tremendously.
Your advisor will be one of the most important people in your PhD. It is essential to have good communication and working chemistry with them. One of the reasons my PhD felt like so much fun is because my advisor and I cared about the same problems.
Form a community and foster friendships with your lab mates, talk about research, or email a colleague whose work moved you and get a coffee with them at a conference. Also, try for opportunities to work with people in your lab or your community. It helps us learn so much.
Researchers from the department presented machine learning and artificial intelligence research at the thirty-fifth Conference on Neural Information Processing Systems (NeurIPS 2022).
Abstract: Identifying the effects of new interventions from data is a significant challenge found across a wide range of the empirical sciences. A well-known strategy for identifying such effects is Pearl’s front-door (FD) criterion. The definition of the FD criterion is declarative, only allowing one to decide whether a specific set satisfies the criterion. In this paper, we present algorithms for finding and enumerating possible sets satisfying the FD criterion in a given causal diagram. These results are useful in facilitating the practical applications of the FD criterion for causal effects estimation and helping scientists to select estimands with desired properties, e.g., based on cost, feasibility of measurement, or statistical power.
Abstract: One common task in many data sciences applications is to answer questions about the effect of new interventions, like: `what would happen to Y if we make X equal to x while observing covariates Z=z?’. Formally, this is known as conditional effect identification, where the goal is to determine whether a post-interventional distribution is computable from the combination of an observational distribution and assumptions about the underlying domain represented by a causal diagram. A plethora of methods was developed for solving this problem, including the celebrated do-calculus [Pearl, 1995]. In practice, these results are not always applicable since they require a fully specified causal diagram as input, which is usually not available. In this paper, we assume as the input of the task a less informative structure known as a partial ancestral graph (PAG), which represents a Markov equivalence class of causal diagrams, learnable from observational data. We make the following contributions under this relaxed setting. First, we introduce a new causal calculus, which subsumes the current state-of-the-art, PAG-calculus. Second, we develop an algorithm for conditional effect identification given a PAG and prove it to be both sound and complete. In words, failure of the algorithm to identify a certain effect implies that this effect is not identifiable by any method. Third, we prove the proposed calculus to be complete for the same task.
Abstract: Combination therapy refers to the use of multiple treatments — such as surgery, medication, and behavioral therapy – to cure a single disease, and has become a cornerstone for treating various conditions including cancer, HIV, and depression. All possible combinations of treatments lead to a collection of treatment regimens (i.e., policies) with mixed scopes, or what physicians could observe and which actions they should take depending on the context. In this paper, we investigate the online reinforcement learning setting for optimizing the policy space with mixed scopes. In particular, we develop novel online algorithms that achieve sublinear regret compared to an optimal agent deployed in the environment. The regret bound has a dependency on the maximal cardinality of the induced state-action space associated with mixed scopes. We further introduce a canonical representation for an arbitrary subset of interventional distributions given a causal diagram, which leads to a non-trivial, minimal representation of the model parameters.
Masked Prediction: A Parameter Identifiability View Bingbin Liu Carnegie Mellon University, Daniel Hsu Columbia University, Pradeep Ravikumar Carnegie Mellon University, Andrej Risteski Carnegie Mellon University
Abstract: The vast majority of work in self-supervised learning have focused on assessing recovered features by a chosen set of downstream tasks. While there are several commonly used benchmark datasets, this lens of feature learning requires assumptions on the downstream tasks which are not inherent to the data distribution itself. In this paper, we present an alternative lens, one of parameter identifiability: assuming data comes from a parametric probabilistic model, we train a self-supervised learning predictor with a suitable parametric form, and ask whether the parameters of the optimal predictor can be used to extract the parameters of the ground truth generative model.Specifically, we focus on latent-variable models capturing sequential structures, namely Hidden Markov Models with both discrete and conditionally Gaussian observations. We focus on masked prediction as the self-supervised learning task and study the optimal masked predictor. We show that parameter identifiability is governed by the task difficulty, which is determined by the choice of data model and the amount of tokens to predict. Technique-wise, we uncover close connections with the uniqueness of tensor rank decompositions, a widely used tool in studying identifiability through the lens of the method of moments.
Abstract: Single-index models are a class of functions given by an unknown univariate link” function applied to an unknown one-dimensional projection of the input. These models are particularly relevant in high dimension, when the data might present low-dimensional structure that learning algorithms should adapt to. While several statistical aspects of this model, such as the sample complexity of recovering the relevant (one-dimensional) subspace, are well-understood, they rely on tailored algorithms that exploit the specific structure of the target function. In this work, we introduce a natural class of shallow neural networks and study its ability to learn single-index models via gradient flow. More precisely, we consider shallow networks in which biases of the neurons are frozen at random initialization. We show that the corresponding optimization landscape is benign, which in turn leads to generalization guarantees that match the near-optimal sample complexity of dedicated semi-parametric methods.
On Scrambling Phenomena for Randomly Initialized Recurrent Networks Evangelos Chatziafratis University of California Santa Cruz, Ioannis Panageas University of California Irvine, Clayton Sanford Columbia University, Stelios Stavroulakis University of California Irvine
Abstract: Recurrent Neural Networks (RNNs) frequently exhibit complicated dynamics, and their sensitivity to the initialization process often renders them notoriously hard to train. Recent works have shed light on such phenomena analyzing when exploding or vanishing gradients may occur, either of which is detrimental for training dynamics. In this paper, we point to a formal connection between RNNs and chaotic dynamical systems and prove a qualitatively stronger phenomenon about RNNs than what exploding gradients seem to suggest. Our main result proves that under standard initialization (e.g., He, Xavier etc.), RNNs will exhibit \textit{Li-Yorke chaos} with \textit{constant} probability \textit{independent} of the network’s width. This explains the experimentally observed phenomenon of \textit{scrambling}, under which trajectories of nearby points may appear to be arbitrarily close during some timesteps, yet will be far away in future timesteps. In stark contrast to their feedforward counterparts, we show that chaotic behavior in RNNs is preserved under small perturbations and that their expressive power remains exponential in the number of feedback iterations. Our technical arguments rely on viewing RNNs as random walks under non-linear activations, and studying the existence of certain types of higher-order fixed points called \textit{periodic points} in order to establish phase transitions from order to chaos.
Patching open-vocabulary models by interpolating weights Gabriel Ilharco University of Washington, Mitchell Wortsman University of Washington, Samir Yitzhak Gadre Columbia University, Shuran Song Columbia University, Hannaneh Hajishirzi University of Washington, Simon Kornblith Google Brain, Ali Farhadi University of Washington, Ludwig Schmidt University of Washington
Abstract: Open-vocabulary models like CLIP achieve high accuracy across many image classification tasks. However, there are still settings where their zero-shot performance is far from optimal. We study model patching, where the goal is to improve accuracy on specific tasks without degrading accuracy on tasks where performance is already adequate. Towards this goal, we introduce PAINT, a patching method that uses interpolations between the weights of a model before fine-tuning and the weights after fine-tuning on a task to be patched. On nine tasks where zero-shot CLIP performs poorly, PAINT increases accuracy by 15 to 60 percentage points while preserving accuracy on ImageNet within one percentage point of the zero-shot model. PAINT also allows a single model to be patched on multiple tasks and improves with model scale. Furthermore, we identify cases of broad transfer, where patching on one task increases accuracy on other tasks even when the tasks have disjoint classes. Finally, we investigate applications beyond common benchmarks such as counting or reducing the impact of typographic attacks on CLIP. Our findings demonstrate that it is possible to expand the set of tasks on which open-vocabulary models achieve high accuracy without re-training them from scratch.
Abstract: We introduce ASPiRe (Adaptive Skill Prior for RL), a new approach that leverages prior experience to accelerate reinforcement learning. Unlike existing methods that learn a single skill prior from a large and diverse dataset, our framework learns a library of different distinction skill priors (i.e., behavior priors) from a collection of specialized datasets, and learns how to combine them to solve a new task. This formulation allows the algorithm to acquire a set of specialized skill priors that are more reusable for downstream tasks; however, it also brings up additional challenges of how to effectively combine these unstructured sets of skill priors to form a new prior for new tasks. Specifically, it requires the agent not only to identify which skill prior(s) to use but also how to combine them (either sequentially or concurrently) to form a new prior. To achieve this goal, ASPiRe includes Adaptive Weight Module (AWM) that learns to infer an adaptive weight assignment between different skill priors and uses them to guide policy learning for downstream tasks via weighted Kullback-Leibler divergences. Our experiments demonstrate that ASPiRe can significantly accelerate the learning of new downstream tasks in the presence of multiple priors and show improvement on competitive baselines.
Language Models with Image Descriptors are Strong Few-Shot Video-Language Learners Zhenhailong Wang Columbia University, Manling Li Columbia University, Ruochen Xu Microsoft, Luowei Zhou Meta, Jie Lei Meta, Xudong Lin Columbia University, Shuohang Wang Microsoft, Ziyi Yang Stanford University, Chenguang Zhu Stanford University, Derek Hoiem University of Illinois, Shih-Fu Chang Columbia University, Mohit Bansal University of North Carolina Chapel Hill, Heng Ji University of Illinois
Abstract: The goal of this work is to build flexible video-language models that can generalize to various video-to-text tasks from few examples. Existing few-shot video-language learners focus exclusively on the encoder, resulting in the absence of a video-to-text decoder to handle generative tasks. Video captioners have been pretrained on large-scale video-language datasets, but they rely heavily on finetuning and lack the ability to generate text for unseen tasks in a few-shot setting. We propose VidIL, a few-shot Video-language Learner via Image and Language models, which demonstrates strong performance on few-shot video-to-text tasks without the necessity of pretraining or finetuning on any video datasets. We use image-language models to translate the video content into frame captions, object, attribute, and event phrases, and compose them into a temporal-aware template. We then instruct a language model, with a prompt containing a few in-context examples, to generate a target output from the composed content. The flexibility of prompting allows the model to capture any form of text input, such as automatic speech recognition (ASR) transcripts. Our experiments demonstrate the power of language models in understanding videos on a wide variety of video-language tasks, including video captioning, video question answering, video caption retrieval, and video future event prediction. Especially, on video future event prediction, our few-shot model significantly outperforms state-of-the-art supervised models trained on large-scale video datasets.Code and processed data are publicly available for research purposes at https://github.com/MikeWangWZHL/VidIL.
Abstract: There has been a significant research effort focused on explaining predictive models, for example through post-hoc explainability and recourse methods. Most of the proposed techniques operate upon a single, fixed, predictive model. However, it is well-known that given a dataset and a predictive task, there may be a multiplicity of models that solve the problem (nearly) equally well. In this work, we investigate the implications of this kind of model indeterminacy on the post-hoc explanations of predictive models. We show how it can lead to explanatory multiplicity, and we explore the underlying drivers. We show how predictive multiplicity, and the related concept of epistemic uncertainty, are not reliable indicators of explanatory multiplicity. We further illustrate how a set of models showing very similar aggregate performance on a test dataset may show large variations in their local explanations, i.e., for a specific input. We explore these effects for Shapley value based explanations on three risk assessment datasets. Our results indicate that model indeterminacy may have a substantial impact on explanations in practice, leading to inconsistent and even contradicting explanations.
Reconsidering Deep Ensembles Taiga Abe Columbia University, Estefany Kelly Buchanan Columbia University, Geoff Pleiss Columbia University, Richard Zemel Columbia University, John Cunningham Columbia University
Abstract: Ensembling neural networks is an effective way to increase accuracy, and can often match the performance of individual larger models. This observation poses a natural question: given the choice between a deep ensemble and a single neural network with similar accuracy, is one preferable over the other? Recent work suggests that deep ensembles may offer distinct benefits beyond predictive power: namely, uncertainty quantification and robustness to dataset shift. In this work, we demonstrate limitations to these purported benefits, and show that a single (but larger) neural network can replicate these qualities. First, we show that ensemble diversity, by any metric, does not meaningfully contribute to an ensemble’s ability to detect out-of-distribution (OOD) data, but is instead highly correlated with the relative improvement of a single larger model. Second, we show that the OOD performance afforded by ensembles is strongly determined by their in-distribution (InD) performance, and – in this sense – is not indicative of any “effective robustness.” While deep ensembles are a practical way to achieve improvements to predictive power, uncertainty quantification, and robustness, our results show that these improvements can be replicated by a (larger) single model
The inaugural fair gave students the opportunity to take their research from paper to presentation and showcase their hard work.
The projects of the Undergraduate Computer and Data Science Research Fair fell under the themes of Data Science and Society, Interdisciplinary Data Science Applications, Data Science and Computer Science Research. Posters and demonstrations were proudly hosted by twenty-five students from SEAS, Barnard College, Columbia College, and the School of General Studies.
CS ChairLuca CarloniandClifford Stein, Interim Director of the Data Science Institute, issued the four awards, including best overall and best in each of the three tracks.
CS & Data Science Research
Improving Model Training via Self-learned Label Representations
Xiao Yu, Senior, SEAS
Interdisciplinary Data Science
Outlier Splicing Analysis of Autism Spectrum Disorder using RNA-seq Data
Sophia Sowinski, Junior, Barnard College
Data Science & Society
Legal and Political Stance Detection of SCOTUS Language
Noah Bergam, Sophomore, Columbia College
Demonstrations
Machine Learning assisted Age-Related Macular Degeneration Detection using Indirect Fundoscopy and iOS Device
Second-year PhD student Cheng Chi talks about how his research on robotic control won a Best Paper Award at RSS 2022
In the Columbia Artificial Intelligence and Robotics (CAIR) Lab, Cheng Chi stands in front of a robotic arm. At the end of the arm sits a yellow plastic cup. His goal at the moment is to use a piece of rope to hit the cup to the ground.
“I never thought I would have to do this as part of a research project,” said Chi, a second-year PhD student. He was conducting the exercise to gain a better understanding of physical movement and how it can be applied to a robotic control system.
Existing robotic systems struggle to precisely manipulate objects with complex dynamics, such as hitting a small target with a whip or swinging tablecloths to an exact location. While these tasks are quite hard even for humans, we usually have a good intuition about how to change our actions after a failed attempt, and iteratively get closer to the goal.
Cheng Chi in the CAIR Lab
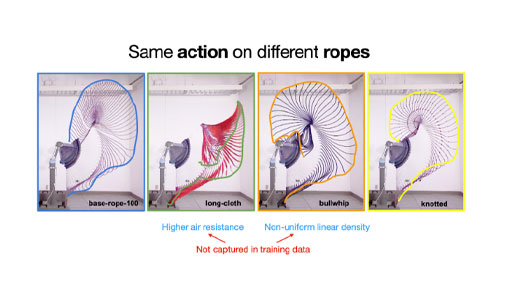
Chi was able to knock the cup off after five tries. Now, it’s the robot’s turn to fling the piece of rope. It takes the robot four times to hit the target during the experiment (in general less than 10 times). The algorithm/neural network was trained in a simulator using a large amount of data. The robot, called Oolong, had to hit a target and was tested on different kinds of ropes it had never seen before.
Together with Assistant Professor Shuran Song and colleagues from the CAIR Lab, Chi worked to formalize this intuition into an algorithm called Iterative Residual Policy (IRP), a general learning framework for repeatable tasks with complex dynamics where a single model was trained using inaccurate simulation data. IRP can learn from that data and hit many targets with unfamiliar ropes in real robotic experiments, reaching sub-inch accuracy, and demonstrating its strong generalization capability.
This research brings robots from factories, where everything is rigid and can be accurately modeled, closer to everyday households filled with dirty laundry, raw vegetables to be washed in the sink, and leftover food to be cleaned from the fridge. It could potentially alleviate the labor shortage in food, retail, and logistics due to the aging population in many parts of the world. This could also enable the automation of simple tasks like changing bed sheets and badges in hospitals with infectious disease patients.
The team won a Best Paper Award at the Robot Science and Systems Conference (RSS 2022). We caught up with Chi to find out more about his research and PhD life at Columbia.
Q: How did you become part of the research project?
This is part of a grant from the Toyota Research Institute on deformable object manipulation. For this specific project, I wanted to explore more complex and dynamic forms of robotic manipulation and control. As the primary researcher of this project, I decided on the research topic, problem, and task.
Q: How long did you work on the project? What did you have to do, or read to prepare to make the system?
The project started in May 2021. I did a lot of research about control theory for underactuated systems, chaos, and how to work with robot hardware.
Classical robotics literature divides the operation of a robot into three stages — perception, planning, and control. In my previous research, I studied perception and the planning stage of robotics. However, I realized that my knowledge still has a noticeable hole in control theory and systems that control the function and movement of robots.
I believe that I will never become a full-fledged roboticist without understanding all parts of robotic operations. Therefore, I intentionally steered this project toward control which allows me to read more into control-related literature and classes.
For example, I went over the YouTube recording of MIT’s underactuated robotics, taught by Professor Russ Tedrake, who has been known for his contributions to the control of locomotion systems (such as Boston Dynamic’s quadruped robots).
Another interesting thing about control is that, unlike planning, the control of the human body mostly happens at a subconscious level. Therefore, understanding more about control also gave me more insight into how the human body works.
The key realization came after months of reflecting on how I achieved certain tasks and how to formulate such a problem.
Since the relatively early stage of this project (after I decided to tackle the rope whipping task), I had this lingering feeling that being able to adjust the next action based on the error of my previous action is critical for how humans accomplish this task (by observing myself doing it). But I wasn’t able to connect it with math and concrete algorithms.
The next few months were spent playing with data collected in simulations to understand the structure of this task and problem. I often spent a few afternoons a week just staring at my iPad notes, sketching potential algorithms that can solve this task efficiently. Most of them were futile. However, one afternoon in late September, I suddenly came up with the idea that connects my lingering feeling to this concrete algorithm. And the rest was mostly planning out experiments, executing, and verifying results.
Q: Why did you decide to do research on robotic control?
I decided on the research project jointly on what is missing in the field and what I wanted to learn. For example, I wanted to get into control last summer, so I took classes online and read relevant papers to build a foundation. I noticed that the missing piece in the field is deformable manipulation with precision.
Existing robotic algorithms often assume the object being manipulated is rigid, and ignore its physics/dynamics, due to its complexity. My research thrust has been targeting this complexity (of object physics and non-rigidity) head-on, which hopefully will result in better algorithms that will improve the overall performance and robustness of robotics systems, outside of confined/structured industrial environments.
Whipping a piece of rope is one of the simplest instances of dynamic deformable object manipulation, without the additional perceptive complexity such as self-occlusion, etc. However, we believe that whipping a piece of rope and tablecloth is representative of the class of problem we are interested in and that there is no existing robotic system/algorithm that can accomplish this task. Therefore, our algorithm has expanded what is considered possible in robotics.
I thought that it would be cool to simplify it to a minimum-working task, like whipping. Whipping a piece of rope or cloth accurately requires adapting existing skills which humans are good at but it is very difficult for robots to do.
Humans can hit targets with reasonable accuracy after usually 10~20 trials. The best algorithm before IRP takes 100-1000+ trials to get there.
The project spanned 10 months and it was not easy, since solving this novel and challenging task requires going beyond the common paradigm in the field, for example, reinforcement learning or system identification.
I tried three ideas at first and none of them worked or advanced the field to a satisfying degree for me. The final idea was inspired by some studies from the biomechanics/neural science community that I came across while doing research.
While I was struggling with this project, my advisor pointed me to this recording of an RSS 2020 workshop. I was fascinated by one of the talks by Professor Dagmar Stenard and her findings from the biomechanical perspective of how humans minimize uncertainty and avoid the chaotic region of the state space when taking actions.
I read further into her publications and was pleasantly surprised that her group was studying the same rope-whipping problem. Their algorithm was crude and they only tested in simulation with many additional assumptions, but I really liked their problem formulation of the whipping task and their use of action primitive, which dramatically reduced the number of parameters needed to describe the dynamic and continuous robot action.
They also demonstrated that their action primitives (that bio literature believes humans also use) are sufficient for this task. Therefore, I took their problem formulation and tweaked their action primitive to better fit real robotic hardware, and eventually developed the IRP algorithm on top of that.
Q: Why did you decide to use different kinds of ropes for the project?
The type of rope we simulated for training is modeled after a thick cotton rope we bought on Amazon. However, due to the various complex physical properties and their effects, the rope modeled in simulation behaves significantly differently from its real-world counterpart. This is an instance of a well-known challenge in the robotics community called “sim2real gap”.
Since the deep-learning revolution (~2014), a large body of robotic algorithms emerged that have shown very promising results in simulated environments. However, they also rely on a large amount of data for training (our algorithm included), which is only feasible to collect in simulation. If the behavior of objects in simulation matches exactly their counterparts in real life, in theory, we can directly apply these data-hungry algorithms to the real world. Unfortunately, this is far from the truth, and the difference is especially big for deformable objects.
The biggest contribution of this paper is providing a solution to close this “sim2real gap” for a limited class of problems (where the actions are repeatable, and the objects can be reset to the original state), i.e. the algorithm behaves just as good in the real world as in simulation, despite the simulation it was trained on is very “wrong”.
To further demonstrate how “wrong” the simulation can be while the algorithm still works, we cut out a long strip of cloth, that behaves like a gymnastic ribbon and treated it as the rope. We also bought a very thick leather bullwhip, that has a non-uniform density (it becomes thinner and thinner as it goes toward the tip), while all ropes we trained in simulation have uniform thickness and density. The experimental results on these two “ropes” were just as good.
Q: What do you think is the most interesting thing about doing research?
I like how researchers are able to try high-risk ideas that actually advance the field and also learn fundamental knowledge about the field. Working in industry usually constrains research options to low-risk ideas, while the engineering effort might be larger.
Q: How did your previous experiences prepare you for a PhD?
I gained my initial research experience during my undergrad at the University of Michigan, working on deformable object perception. I had multiple internships, as well as full-time jobs at autonomous vehicle companies, which taught me how to properly engineer a robotics software system.
Q: Why did you apply to Columbia and how was that process?
I applied to Columbia to work with Assistant Professor Shuran Song. Just before I graduated from undergrad, Shuran did a job talk at the University of Michigan. My undergrad research advisor Professor Dmitry Berenson was at her talk and he was really impressed. Berenson strongly recommended that I apply to work with her and he thought we would be a great fit. After researching her past publications, I did find a large overlap in our research interests and I only heard good words about her after asking other people who have worked with her.
At the time, I wasn’t really sure about getting a PhD, and because of the time needed to complete the applications, I only applied to two schools. The application website could have been improved, but the overall process is surprisingly smooth. I really like the idea that students are admitted by and to individual professors, and the professors make the decision.
Q: What has been the highlight of your time at Columbia?
The highlight of my time is being able to be taught and guided by my advisor, as well as other PhD students.
Q: You are starting the third year of your PhD at Columbia, do you think your skills have improved? In which ways?
I think what improved the most was to think more structurally and not be buried by the details. Due to the engineering complexity of robotic systems, there are thousands of variables and decisions, large and small, I needed to make for the project to progress. For example, on the high level, how to model the rope in the simulation, how to model the robot, how to represent the observation and actions, how the model should be architected, etc.
For an inexperienced researcher like myself, it is not obvious which one of these parameters will make or break the project, or will only yield a small change in the final performance. So, I over-analyzed, over-engineered, and over-thought the small problems. Fortunately, Shuran often called out that some of these decisions probably don’t matter that much, and choosing an arbitrary path to go forward is strictly better than spending time thinking about which one is better.
The problem is that this is mostly based on intuition. Shuran can’t always give evidence of why one thing doesn’t matter and why another does. But fortunately, I think I am getting a better grasp of these intuitions. It will become easier for me as time passes and I become an expert in robotics.
I also have found that it is really important to communicate clearly, both in meetings and when writing things down for reports or even emails. Learning by example from my advisor also helps a lot.
Q: What is your advice to students on how to navigate their time at Columbia? If they want to do research what should they know or do to prepare?
New students going into research should try as hard as possible to push through the first research project. It is always hard in the beginning, and it might feel impossible, but you can do it. Build up a tolerance for failure and continue to try different things, which is often critical to making a contribution to the field.
Michelle Zhou (PhD ’99) explains what no-code AI means and presents five inflection points that led to her current work, including the impact of two professors in graduate school who helped her find her direction in AI.
Influential computer scientist Kathy McKeown heads up two multi-million dollar grants—one to analyze cross-cultural norms and another to better understand grief in the Black community.
Abstract Multi-group agnostic learning is a formal learning criterion that is concerned with the conditional risks of predictors within subgroups of a population. The criterion addresses recent practical concerns such as subgroup fairness and hidden stratification. This paper studies the structure of solutions to the multi-group learning problem and provides simple and near-optimal algorithms for the learning problem.
On Measuring Causal Contributions Aia Do-Interventions Yonghan Jung Purdue University, Shiva Kasiviswanathan Amazon, Jin Tian Iowa State University, Dominik Janzing Amazon, Patrick Bloebaum Amazon, Elias Bareinboim Columbia University
Abstract Causal contributions measure the strengths of different causes to a target quantity. Understanding causal contributions is important in empirical sciences and data-driven disciplines since it allows to answer practical queries like “what are the contributions of each cause to the effect?” In this paper, we develop a principled method for quantifying causal contributions. First, we provide desiderata of properties (axioms) that causal contribution measures should satisfy and propose the do-Shapley values (inspired by do-interventions (Pearl, 2000)) as a unique method satisfying these properties. Next, we develop a criterion under which the do-Shapley values can be efficiently inferred from non-experimental data. Finally, we provide do-Shapley estimators exhibiting consistency, computational feasibility, and statistical robustness. Simulation results corroborate with the theory.
Abstract This paper investigates the problem of bounding counterfactual queries from an arbitrary collection of observational and experimental distributions and qualitative knowledge about the underlying data-generating model represented in the form of a causal diagram. We show that all counterfactual distributions in an arbitrary structural causal model (SCM) with discrete observed domains could be generated by a canonical family of SCMs with the same causal diagram where unobserved (exogenous) variables are also discrete, taking values in finite domains. Utilizing the canonical SCMs, we translate the problem of bounding counterfactuals into that of polynomial programming whose solution provides optimal bounds for the counterfactual query. Solving such polynomial programs is in general computationally expensive. We then develop effective Monte Carlo algorithms to approximate optimal bounds from a combination of observational and experimental data. Our algorithms are validated extensively on synthetic and real-world datasets.
Abstract Generalizing causal knowledge across environments is a common challenge shared across many of the data-driven disciplines, including AI and ML. Experiments are usually performed in one environment (e.g., in a lab, on Earth, in a training ground), almost invariably, with the intent of being used elsewhere (e.g., outside the lab, on Mars, in the real world), in an environment that is related but somewhat different than the original one, where certain conditions and mechanisms are likely to change. This generalization task has been studied in the causal inference literature under the rubric of transportability (Pearl and Bareinboim, 2011). While most transportability works focused on generalizing associational and interventional distributions, the generalization of counterfactual distributions has not been formally studied. In this paper, we investigate the transportability of counterfactuals from an arbitrary combination of observational and experimental distributions coming from disparate domains. Specifically, we introduce a sufficient and necessary graphical condition and develop an efficient, sound, and complete algorithm for transporting counterfactual quantities across domains in nonparametric settings. Failure of the algorithm implies the impossibility of generalizing the target counterfactual from the available data without further assumptions.
Abstract We introduce the unbounded depth neural network (UDN), an infinitely deep probabilistic model that adapts its complexity to the training data. The UDN contains an infinite sequence of hidden layers and places an unbounded prior on a truncation ℓ, the layer from which it produces its data. Given a dataset of observations, the posterior UDN provides a conditional distribution of both the parameters of the infinite neural network and its truncation. We develop a novel variational inference algorithm to approximate this posterior, optimizing a distribution of the neural network weights and of the truncation depth ℓ, and without any upper limit on ℓ. To this end, the variational family has a special structure: it models neural network weights of arbitrary depth, and it dynamically creates or removes free variational parameters as its distribution of the truncation is optimized. (Unlike heuristic approaches to model search, it is solely through gradient-based optimization that this algorithm explores the space of truncations.) We study the UDN on real and synthetic data. We find that the UDN adapts its posterior depth to the dataset complexity; it outperforms standard neural networks of similar computational complexity; and it outperforms other approaches to infinite-depth neural networks.
XRP: In-Kernel Storage Functions with eBPF Yuhong Zhong Columbia University, Haoyu Li Columbia University, Yu Jian Wu Columbia University, Ioannis Zarkadas Columbia University, Jeffrey Tao Columbia University, Evan Mesterhazy Columbia University, Michael Makris Columbia University, Junfeng Yang Columbia University, Amy Tai Google, Ryan Stutsman University of Utah; Asaf Cidon Columbia University
Abstract: With the emergence of microsecond-scale NVMe storage devices, the Linux kernel storage stack overhead has become significant, almost doubling access times. We present XRP, a framework that allows applications to execute user-defined storage functions, such as index lookups or aggregations, from an eBPF hook in the NVMe driver, safely bypassing most of the kernel’s storage stack. To preserve file system semantics, XRP propagates a small amount of kernel state to its NVMe driver hook where the user-registered eBPF functions are called. We show how two key-value stores, BPF-KV, a simple B+-tree key-value store, and WiredTiger, a popular log-structured merge tree storage engine, can leverage XRP to significantly improve throughput and latency.
ROLLER: Fast and Efficient Tensor Compilation for Deep Learning Hongyu Zhu University of Toronto and Microsoft Research; Ruofan Wu Renmin University of China and Microsoft Research; Yijia Diao Shanghai Jiao Tong University and Microsoft Research, Shanbin Ke UCSD and Microsoft Research, Haoyu Li Columbia University and Microsoft Research; Chen Zhang Tsinghua University and Microsoft Research; Jilong Xue Microsoft Research, Lingxiao Ma Microsoft Research, Yuqing Xia Microsoft Research, Wei Cui Microsoft Research, Fan Yang Microsoft Research, Mao Yang Microsoft Research, Lidong Zhou Microsoft Research, Asaf Cidon Columbia University, Gennady Pekhimenko University of Toronto
Abstract: Despite recent advances in tensor compilers, it often costs hours to generate an efficient kernel for an operator, a compute-intensive sub-task in a deep neural network (DNN), on various accelerators (e.g., GPUs). This significantly slows down DNN development cycles and incurs heavy burdens on the development of general kernel libraries and custom kernels, especially for new hardware vendors. The slow compilation process is due to the large search space formulated by existing DNN compilers, which have to use machine learning algorithms to find good solutions.
In this paper, we present ROLLER, which takes a different construction-based approach to generate kernels. At the core of ROLLER is rTile, a new tile abstraction that encapsulates tensor shapes that align with the key features of the underlying accelerator, thus achieving efficient execution by limiting the shape choices. ROLLER then adopts a recursive rTile-based construction algorithm to generate rTile-based programs (rProgram), whose performance can be evaluated efficiently with a micro-performance model without being evaluated in a real device. As a result, ROLLER can generate efficient kernels in seconds, with comparable performance to the state-of-the-art solutions on popular accelerators like GPUs, while offering better kernels on less mature accelerators like IPUs.
Abstract: The increasing use of sensitive private data in computing is matched by a growing concern regarding data privacy. System software such as hypervisors and operating systems are supposed to protect and isolate applications and their private data, but their large codebases contain many vulnerabilities that can risk data confidentiality and integrity. We introduce Realms, a new abstraction for confidential computing to protect the data confidentiality and integrity of virtual machines. Hardware creates and enforces Realm world, a new physical address space for Realms. Firmware controls the hardware to secure Realms and handles requests from untrusted system software to manage Realms, including creating and running them. Untrusted system software retains control of the dynamic allocation of memory to Realms, but cannot access Realm memory contents, even if run at a higher privileged level. To guarantee the security of Realms, we verified the firmware, introducing novel verification techniques that enable us to prove, for the first time, the security and correctness of concurrent software with hand-over-hand locking and dynamically allocated shared page tables, data races in kernel code running on relaxed memory hardware, integrated C and Arm assembly code calling one another, and untrusted software being in full control of allocating system resources. Realms are included in the Arm Confidential Compute Architecture.
Abstract: Distributed systems are complex and difficult to build correctly. Formal verification can provably rule out bugs in such systems, but finding an inductive invariant that implies the safety property of the system is often the hardest part of the proof. We present DuoAI, an automated system that quickly finds inductive invariants for verifying distributed protocols by reducing SMT query costs in checking invariants with existential quantifiers. DuoAI enumerates the strongest candidate invariants that hold on validate states from protocol simulations, then applies two methods in parallel, returning the result from the method that succeeds first. One checks all candidate invariants and weakens them as needed until it finds an inductive invariant that implies the safety property. Another checks invariants without existential quantifiers to find an inductive invariant without the safety property, then adds candidate invariants with existential quantifiers to strengthen it until the safety property holds. Both methods are guaranteed to find an inductive invariant that proves desired safety properties, if one exists, but the first reduces SMT query costs when more candidate invariants with existential quantifiers are needed, while the second reduces SMT query costs when few candidate invariants with existential quantifiers suffice. We show that DuoAI verifies more than two dozen common distributed protocols automatically, including various versions of Paxos, and outperforms alternative methods both in the number of protocols it verifies and the speed at which it does so, including solving Paxos more than two orders of magnitude faster than previous methods.
Abstract: Containers are widely deployed to package, isolate, and multiplex applications on shared computing infrastructure, but rely on the operating system to enforce their security guarantees. This poses a significant security risk as large operating system codebases contain many vulnerabilities. We have created BlackBox, a new container architecture that provides fine-grain protection of application data confidentiality and integrity without trusting the operating system. BlackBox introduces a container security monitor, a small trusted computing base that creates protected physical address spaces (PPASes) for each container such that there is no direct information flow from container to operating system or other container PPASes. Indirect information flow can only happen through the monitor, which only copies data between container PPASes and the operating system as system call arguments, encrypting data as needed to protect interprocess communication through the operating system. Containerized applications do not need to be modified, can still make use of operating system services via system calls, yet their CPU and memory state are isolated and protected from other containers and the operating system. We have implemented BlackBox by leveraging Arm hardware virtualization support, using nested paging to enforce PPASes. The trusted computing base is a few thousand lines of code, many orders of magnitude less than Linux, yet supports widely-used Linux containers with only modest modifications to the Linux kernel. We show that BlackBox provides superior security guarantees over traditional hypervisor and container architectures with only modest performance overhead on real application workloads.
Abstract: Applications often have fast-paced release schedules, but adoption of software dependency updates can lag by years, leaving applications susceptible to security risks and unexpected breakage. To address this problem, we present UPGRADVISOR, a system that reduces developer effort in evaluating dependency updates and can, in many cases, automatically determine which updates are backward-compatible versus API-breaking. UPGRADVISOR introduces a novel co-designed static analysis and dynamic tracing mechanism to gauge the scope and effect of dependency updates on an application. Static analysis prunes changes irrelevant to an application and clusters relevant ones into targets. Dynamic tracing needs to focus only on whether targets affect an application, making it fast and accurate. UPGRADVISOR handles dynamic interpreted languages and introduces call graph over-approximation to account for their lack of type information and selective hardware tracing to capture program execution while ignoring interpreter machinery.
We have implemented UPGRADVISOR for Python and evaluated it on 172 dependency updates previously blocked from being adopted in widely-used open-source software, including Django, aws-cli, tfx, and Celery. UPGRADVISOR automatically determined that 56% of dependencies were safe to update and reduced by more than an order of magnitude the number of code changes that needed to be considered by dynamic tracing. Evaluating UPGRADVISOR’s tracer in a production-like environment incurred only 3% overhead on average, making it fast enough to deploy in practice. We submitted safe updates that were previously blocked as pull requests for nine projects, and their developers have already merged most of them.
Dean Boyce's statement on amicus brief filed by President Bollinger
President Bollinger announced that Columbia University along with many other academic institutions (sixteen, including all Ivy League universities) filed an amicus brief in the U.S. District Court for the Eastern District of New York challenging the Executive Order regarding immigrants from seven designated countries and refugees. Among other things, the brief asserts that “safety and security concerns can be addressed in a manner that is consistent with the values America has always stood for, including the free flow of ideas and people across borders and the welcoming of immigrants to our universities.”
This recent action provides a moment for us to collectively reflect on our community within Columbia Engineering and the importance of our commitment to maintaining an open and welcoming community for all students, faculty, researchers and administrative staff. As a School of Engineering and Applied Science, we are fortunate to attract students and faculty from diverse backgrounds, from across the country, and from around the world. It is a great benefit to be able to gather engineers and scientists of so many different perspectives and talents – all with a commitment to learning, a focus on pushing the frontiers of knowledge and discovery, and with a passion for translating our work to impact humanity.
I am proud of our community, and wish to take this opportunity to reinforce our collective commitment to maintaining an open and collegial environment. We are fortunate to have the privilege to learn from one another, and to study, work, and live together in such a dynamic and vibrant place as Columbia.
Sincerely,
Mary C. Boyce
Dean of Engineering
Morris A. and Alma Schapiro Professor