FREP awards grants to faculty members in support of research to enhance people’s lives by improving the internet. FREP was founded in 2012 to foster cutting-edge collaborations between scientists in academic settings and those at Yahoo Research.
The application performance testing company NimbleDroid was recently acquired by mobile performance platform HeadSpin. Co-founded by professor Junfeng Yang and PhD student Younghoon Jeon, the tool is used to detect bugs and performance bottlenecks during the development and testing phase of mobile apps and websites.
“I’ve always liked programming but hated the manual debugging process,” said Junfeng Yang, who joined the department in 2008. “So I thought it would be good to use artificial intelligence and program analysis to automate the task of debugging.”
NimbleDroid
scans apps for bugs and bottlenecks and sends a report back with a list of
issues. The New
York Times wrote about
how they used it to identify bottleneck issues with the start up time of their
android app and speed it up by four times. Pinterest also used
the tool during
a testing phase and was able to resolve issues within 21 hours. Previously they
would hear about problems from users once the app was already released, and spent
“multiple days” to identify and fix the problems.
NimbleDroid
has a premier list of customers, some of which also use HeadSpin. These common customers connected Yang and HeadSpin’s
CEO Manish Lachwani. They thought that NimbleDroid would be a great addition to
HeadSpin’s suite of mobile testing and performance solutions. The acquisition was recently announced with Yang
named as Chief Scientist of HeadSpin.
Because the
initial technology for NimbleDroid started at Columbia, Yang and Jeon worked
with Columbia Technology Ventures (CTV) to license the technology.
They started a company, got the exclusive license for the technology, and
further developed the tool. CTV is the technology transfer office that
facilitates the transition of inventions from academic research labs to the
market.
“We are
excited that our research is widely used by unicorn and Fortune 1000 companies
and helps over a billion users,” said Yang. “But our work is not done, we are
developing more technologies to make it easy to launch better software faster.”
Professor Vishal Misra is an avid fan of cricket and now works on research that looks at the vast amount of data on the sport.
“I live in two worlds – one where I am a computer science professor and the other where I am ‘the cricket guy’,” said Vishal Misra, who has been with the department since 2001 and recently received the Distinguished Alumnus of IIT Bombay award.
For the most part, Misra has kept these two worlds separate until last year when he worked on research with colleagues at MIT that forecasts the evolution or progress of the score of a cricket match.
When a game is affected by rain and is cut short, there is a statistical system in place – the Duckworth-Lewis-Stern System which either resets the target or declares the winner if no more play is possible. Their analysis showed that the current method is biased and they developed a better method based on the same ideas that are used to predict the evolution of the game. Their algorithm looks at data of past games and the current game and uses the theory of robust synthetic control to come up with a prediction that is surprisingly accurate.
The first time Misra became involved in the techie side of cricket was through CricInfo, the go-to website for anything to do with the sport. (It is now owned by ESPN.)
Misra (in the middle) on the cricket field, 2014.
In the early 90s, during the internet’s infancy, fans would “meet” and chat in IRC (internet relay chat) chat rooms to talk about the sport. This was a godsend for Misra who had moved to the United States from India for graduate studies at the University of Massachusetts Amherst. Cricket was (and still is) not that popular here but imagine living in 1993 and not be able to hop onto a computer or a smartphone to find out the latest scores? He would call home or go to a bookstore in Boston to buy Indian sports magazines like Sportstar and India Today.
Through the #cricket chatrooms, he met CricInfo’s founder Simon King and they developed the first website with the help of other volunteers spread across the globe. Misra shared, “It was a site by the fans for the fans, that was always the priority.” They also launched live scorecards and game coverage of the 1996 world championships. Misra wrote about the experience for CricInfo’s 20th anniversary. He stuck with his PhD studies and remained in the US when CricInfo became a proper business and opened an office in England.
“I did a lot of coding
back then but my first computer science class was the one I taught here in
Columbia,” said Misra, who studied electrical engineering for his undergraduate
and graduate degrees and joined the department as an assistant professor.
For his PhD thesis, he developed a stochastic differential equation model for TCP, the protocol that carries almost all of the internet’s data traffic. Some of the work he did with colleagues to create a congestion control mechanism based on that model has become part of the internet standard and runs on every cable modem in the world. Cisco took the basic mechanism that they developed, adapted it, and pushed it for standardization. “That gives me a big kick,” said Misra. “That algorithm is actually running almost everywhere.”
Since then his research focus has been on networking and now includes work on internet economics. Richard Ma, a former PhD student who is now faculty at National University Singapore, introduced him to this area. They studied network neutrality issues very early on which led to his playing an active part in the net neutrality debate in India, working with the government, regulators, and citizen activists. “India now has the strongest pro-consumer regulations anywhere in the world, which mirrors the definition I proposed of network neutrality,” he said.
For now, he continues research on net neutrality and differential pricing. He is also working on data center networking research with Google, where he is a visiting scientist. Another paper that generalizes the theory of synthetic control and applies the generalized theory to cricket is in the works. The new paper makes a fundamental contribution to the theory of synthetic control and as a fun application, they used it to study cricket.
“While I continue my work in networking, I am really
excited about the applications of generalized synthetic control. It is a tool
that is going to become incredibly important in all aspects of society,” said
Misra. “It can be used in applications from studying the impact of a
legislation or policy to algorithmic changes in some system – to predicting
cricket scores!”
Columbia researchers presented their work at the Empirical Methods in Natural Language Processing (EMNLP) in Brussels, Belgium.
Professor Julia Hirschberg gave a keynote talk on the work done by the Spoken Language Processing Group on how to automatically detect deception in spoken language – how to identify cues in trusted speech vs. mistrusted speech and how these features differ by speaker and by listener. Slides from the talk can be viewed here.
Five teams with computer science undergrad and PhD students from the Natural Language Processing Group (NLP) also attended the conference to showcase their work on text summarization, analysis of social media, and fact checking.
”Given the difficult times, we are living in, it’s extremely necessary to be perfect with our facts,” said Tuhin Chakrabarty, lead researcher of the paper. “Misinformation spreads like wildfire and has long-lasting impacts. This motivated us to delve into the area of fact extraction and verification.”
This paper presents the ColumbiaNLP
submission for the FEVER Workshop Shared Task. Their system is an end-to-end pipeline that
extracts factual evidence from Wikipedia and infers a decision about the
truthfulness of the claim based on the extracted evidence.
Fact checking is a type
of investigative journalism where experts examine the claims published by
others for their veracity. The claims can range from statements made by public
figures to stories reported by other publishers. The end goal of a fact
checking system is to provide a verdict on whether the claim is true, false, or
mixed. Several organizations such as FactCheck.org and PolitiFact are devoted
to such activities.
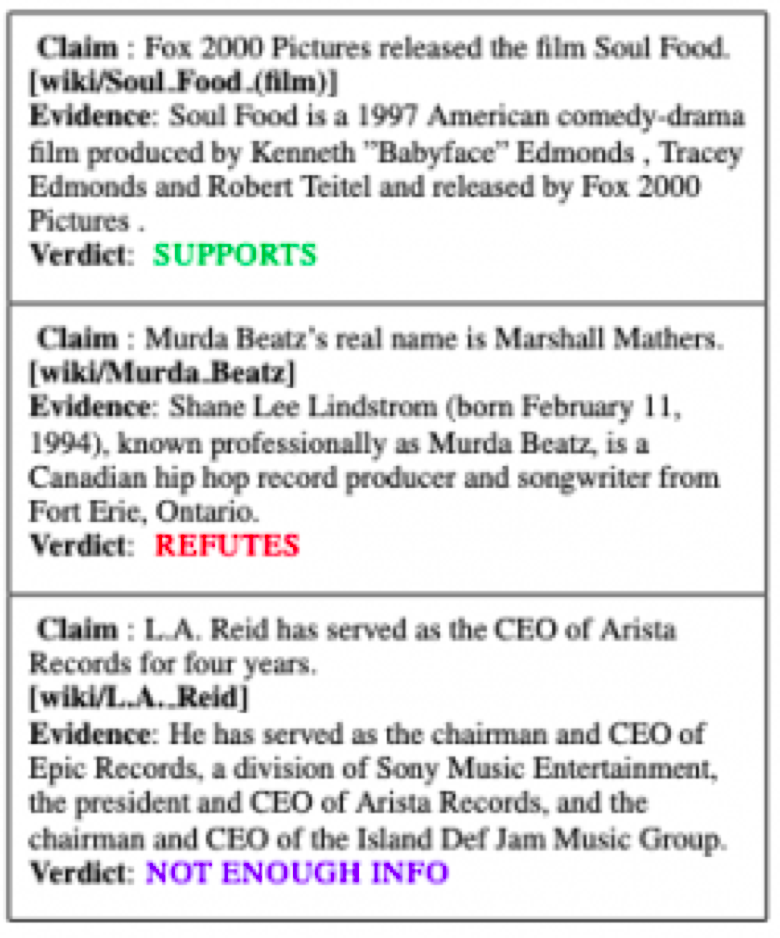
The FEVER Shared task aims to evaluate the ability of a system to verify information using evidence from Wikipedia. Given a claim involving one or more entities (mapping to Wikipedia pages), the system must extract textual evidence (sets of sentences from Wikipedia pages) that supports or refutes the claim and then using this evidence, it must label the claim as Supported, Refuted or NotEnoughInfo.
Detecting Gang-Involved Escalation on Social Media Using Context Serina Chang Computer Science Department, Ruiqi Zhong Computer Science Department, Ethan Adams Computer Science Department, Fei-Tzin Lee Computer Science Department, Siddharth Varia Computer Science Department, Desmond Patton School of Social Work, William Frey School of Social Work, Chris Kedzie Computer Science Department, and Kathleen McKeown Computer Science Department
This research is a
collaboration between Professor Kathy McKeown’s NLP lab and the
Columbia School of Social Work. Professor Desmond Patton, from the School of Social Work and a member of the Data
Science Institute, discovered that gang-involved youth in cities such as
Chicago increasingly turn to social media to grieve the loss of loved ones,
which may escalate into aggression toward rival gangs and plans for violence.
The team created a machine
learning system that can automatically detect aggression and loss in the social
media posts of gang-involved youth. They developed an approach with the hope to
eventually use a system that can save critical time, scale reach, and intervene
before more young lives are lost.
The
system features the use of word embeddings and lexicons, automatically derived
from a large domain-specific corpus which the team constructed. They also
created context features that capture user’s recent posts, both in semantic and
emotional content, and their interactions with other users in the dataset.
Incorporating domain-specific resources and context feature in a Convolutional
Neural Network (CNN) that leads to a significant improvement over the prior
state-of-the-art.
The dataset used spans the public Twitter posts of nearly 300 users from a gang-involved community in Chicago. Youth volunteers and violence prevention organizations helped identify users and annotate the dataset for aggression and loss. Here are two examples of labeled tweets, both of which the system was able to classify correctly. Names are blocked out to preserve the privacy of users.
Tweet examples
For semantics, which were represented by word embeddings, the researchers found that it was optimal to include 90 days of recent tweet history. While for emotion, where an emotion lexicon was employed, only two days of recent tweets were needed. This matched insight from prior social work research, which found that loss is significantly likely to precede aggression in a two-day window. They also found that emotions fluctuate more quickly than semantics so the tighter context window would be able to capture more fine-grained fluctuation.
“We took this context-driven approach because we believed that interpreting emotion in a given tweet requires context, including what the users had been saying recently, how they had been feeling, and their social dynamics with others,” said Serina Chang, an undergraduate computer science student. One thing that surprised them was the extent to which different types of context offered different types of information, as demonstrated by the contrasting contributions of the semantic-based user history feature and the emotion-based one. Continued Chang, “As we hypothesized, adding context did result in a significant performance improvement in our neural net model.”
Automated fact checking of textual claims is of increasing interest in today’s world. Previous research has investigated fact checking in political statements, news articles, and community forums.
“Through our model we can fact check claims
and find specific statements that support the evidence,” said Christopher Hidey,
a fourth year PhD student. “This is a step towards addressing the
propagation of misinformation online.”
As part of the FEVER community
shared task, the researchers developed models that given a statement would jointly find a Wikipedia article and a sentence related
to the statement, and then predict whether the statement is supported by that sentence.
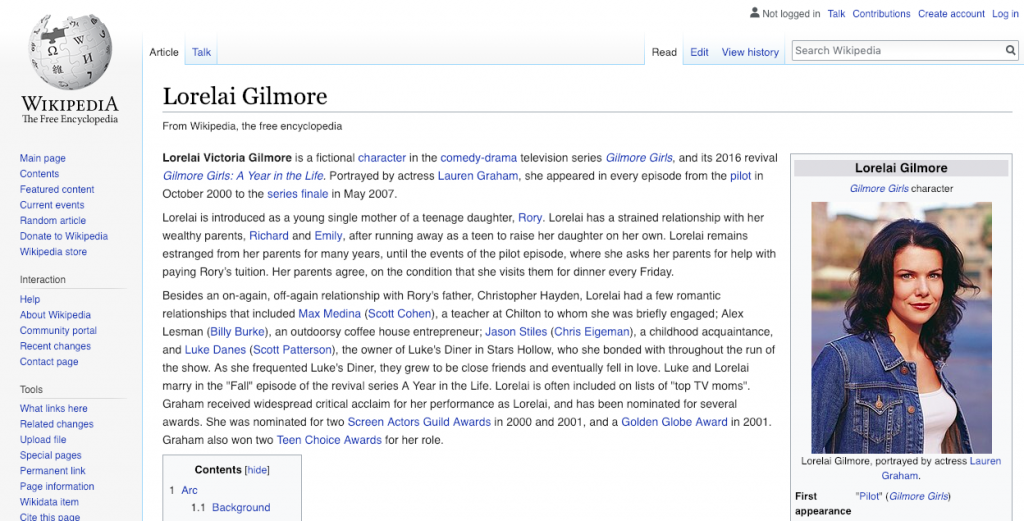
For example, given the claim “Lorelai Gilmore’s father is named Robert,” one could find the Wikipedia article on Lorelai Gilmore and extract the third sentence “Lorelai has a strained relationship with her wealthy parents, Richard and Emily, after running away as a teen to raise her daughter on her own” to show that the claim is false.
Credit : Wikipedia – https://en.wikipedia.org/wiki/Lorelai_Gilmore
One aspect of this problem that the team observed was how poorly TF-IDF, a standard technique in information retrieval and natural language processing, performed at retrieving Wikipedia articles and sentences. Their custom model improved performance by 35 points in terms of recall over a TF-IDF baseline, achieving 90% recall for 5 articles. Overall, the model retrieved the correct sentence and predicted the veracity of the claim 50% of the time.
The rate of which misinformation is spreading on
the web is faster than the rate of manual fact-checking conducted by
organizations like Politifact.com and Factchecking.org. For this paper the
researchers wanted to explore how to automate parts or all of the fact-checking
process. A poster with their findings was presented as part
of the FEVER workshop.
“In order to come up with reliable fact-checking
systems we need to understand the current manual process and identify
opportunities for automation,” said Tariq Alhindi, lead author on the paper. They looked at the LIAR dataset – around 10,000 claims classified by Politifact.com to one of six
degrees of truth – pants-on-fire, false, mostly-false, half-true, mostly-true,
true. Continued Alhindi, we also looked at the fact-checking article for each
claim and automatically extracted justification sentences of a given
verdict and used them in our models, after removing all sentences that contain
the verdict (e.g. true or false).
Excerpt from the LIAR-PLUS dataset
Feature-based machine learning models and
neural networks were used to develop models that can predict whether
a given statement is true or false. Results showed that using some sort of
justification or evidence always improves the results of fake-news detection
models.
“What was most surprising about the results is that
adding features from the extracted justification sentences consistently improved
the results no matter what classifier we used or what other features we
included,” shared Alhindi, a PhD student. “However, we were surprised that the
improvement was consistent even when we compare
traditional feature-based linear machine learning models against state of
the art deep learning models.”
Their research extends the previous work done on this data set which only looked at the linguistic cues of the claim and/or the metadata of the speaker (history, venue, party-affiliation, etc.). The researchers also released the extended dataset to the community to allow further work on this dataset with the extracted justifications.
Recently,
a specific type of machine learning, called deep learning, has made strides in
reaching human level performance on hard to articulate problems, that is,
things people do subconsciously like recognizing faces or understanding speech.
And so, natural language processing researchers have turned to these models for
the task of identifying the most important phrases and sentences in text
documents, and have trained them to imitate the decisions a human editor might
make when selecting content for a summary.
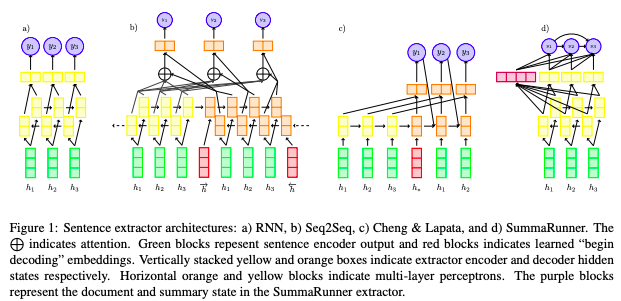
“Deep
learning models have been successful in summarizing natural language texts,
news articles and online comments,” said Chris Kedzie, a fifth
year PhD student. “What we wanted to know is how they are doing it.”
While
these deep learning models are empirically successful, it is not clear how they
are performing this task. By design, they are learning to create their own
representation of words and sentences, and then using them to predict whether a
sentence is important – if it should go into a summary of the document. But
just what kinds of information are they using to create these
representations?
One
hypotheses the researchers had was that certain types of words were more
informative than others. For example, in a news article, nouns and verbs might
be more important than adjectives and adverbs for identifying the most
important information since such articles are typically written in a relatively
objective manner.
To see if this was so, they trained models to predict sentence importance on redacted datasets, where either nouns, verbs, adjectives, adverbs, or function words were removed and compared them to models trained on the original data.
On
a dataset of personal stories published on Reddit, adjectives and adverbs were
the key to achieving the best performance. This made intuitive sense in that
people tend to use intensifiers to highlight the most important or climactic
moments in their stories with sentences like, “And those were the WORST
customers I ever served.”
What surprised the researchers were the news articles – removing any one class of words did not dramatically decrease model performance. Either important content was broadly distributed across all kinds of words or there was some other signal that the model was using.
They suspected that sentence order was important because journalists are typically instructed to write according to the inverted pyramid style with the most important information at the top of the article. It was possible that the models were implicitly learning this and simply selecting sentences from the article lead.
Two pieces of evidence confirmed this. First, looking at a histogram of sentence positions selected as important, the models overwhelmingly preferred the lead of the article. Second, in a follow up experiment, the sentence ordered was shuffled to remove sentence position as a viable signal from which to learn. On news articles, model performance dropped significantly, leading to the conclusion that sentence position was most responsible for model performance on news documents.
The
result concerned the researchers as they want models to be trained to truly
understand human language and not use simple and brittle heuristics (like
sentence position). “To connect this to broader trends in machine learning, we
should be very concerned and careful about what signals are being exploited by
our models, especially when making sensitive decisions,” Kedzie continued. ”The
signals identified by the model as helpful may not truly capture the problem we
are trying to solve, and worse yet, may be exploiting biases in the dataset
that we do not wish it to learn.”
However,
Kedzie sees this as an opportunity to improve the utility of word
representations so that models are better able to use the article content
itself. Along these lines, in the future, he hopes to show that by quantifying
the surprisal or novelty of a particular word or phrase, models are able to
make better sentence importance predictions. Just as people might remember the
most surprising and unexpected parts of a good story.
Hwang spent the summer working for the Natural Language Text Processing Lab (NLP) and the Data Science Institute (DSI) on a joint project, doing research on gang violence in Chicago.
What was the topic/central focus of your research project?
I used the DSI’s Deep Neural Inspector to evaluate an NLP model that classified Tweets from gang-related users.
What were your findings?
Through my research, I found that the DNI reported higher correlation between hypothesis functions and neuron/layer output in trained models than random models, which confirms that the models learn how to classify the data input.
The aggression model showed interesting correlation with activation hypotheses, and the same with the loss model with imagery, which implies that aggressive speech tends to be very active (intense) and that text containing loss tend to use language that is concrete rather than abstract. If I had more time to continue this research, I would love to explore different types and sentiments in text and how that would affect how well a model learns its task.
What about the project did you find interesting?
The most interesting part of my research was seeing how interconnected all of these disciplines are. I split most of my time between the Natural Language Processing Lab and the Data Science Institute, but I also had the chance to meet some great people from the School of Social Work–their work on gang-related speech is part of an even bigger project to predict, and later prevent, violence based on social media data.
How did you get involved in/ choose this project?
I’ve been working at the NLP Lab since freshman year and decided to continue working there over the summer. In my opinion research is one of the best ways to develop your skillset and ask questions to people already established in the same field. I knew I wanted to pursue research even before I decided to major in computer science, and I feel so grateful to be included in a lab that combines so many of my interests and develops technology that matters.
How much time did it take and who did you work with?
The project was for three months and I worked with CS faculty – Professor Kathy McKeown and Professor Eugene Wu.
Which CS classes were most helpful in putting this project together?
Python, Data Structures
What were some obstacles you faced in working on this project?
I had just finished my sophomore year when I tackled this project, which means that the most advanced class I had taken at that point was Advanced Programming. I spent a lot of time just learning: figuring out how machine learning models work, reading a natural language processing textbook, and even conducting a literature review on violence, social media, and Chicago gangs just so I could familiarize myself with the dataset. I felt that I had to absorb an enormous amount of information all at once, which was intimidating, but I was surrounded by people with infinite patience for all of my questions.
What were some positives of this project?
Through this project, I really started to appreciate how accessible computer science is. Half of the answers we need are already out on the internet. The other half is exactly why we need research. I can learn an entire CS language for free in a matter of days thanks to all of these online resources, but it takes a bit more effort to answer the questions I am interested in: what makes text persuasive? What’s a fair way of summarizing emotional multi-document texts?
Can you discuss your experience presenting?
Along with the Columbia Summer Symposium, I have presented my research at the Harvard National Collegiate Research Conference and the Stanford Research Conference.
Do you plan to present this research at any other events/conferences?
Yes, but I have yet to hear if I have been accepted.
What do you plan to do with your CS undergraduate degree?
Not sure yet but definitely something in the natural language understanding/software engineering space.
Do you see yourself pursuing research after graduation?
Yes! I loved working on a project that mattered and added good to the world beyond just technology. I also loved presenting my research because it inspired me to think beyond my project: what more can we do, how can others use this research, and how can we keep thinking bigger?
In light of how easy it is to identify people based on their DNA, researchers suggest ways to protect genetic information.
Genetic information uploaded to a website is now used to help identify criminals. This technique, employed by law enforcement to solve the Golden State Killer case, took genetic material from the crime scene and compared it to publicly available genetic information on third party website GEDmatch.
Inspired by how the Golden State Killer was caught, researchers set out to see just how easy it is to identify individuals by searching databases and finding genetic matches through distant relatives. The paper out today in Science Magazine also proposes a way to protect genetic information.
“We want people to discover their genetic data,” said the paper’s lead author, Yaniv Erlich, a computer scientist at Columbia University and Chief Science Officer at MyHeritage, a genealogy and DNA testing company. “But we have to think about how to keep people safe and prevent issues.”
Commercially available genetic tests are increasingly popular and users can opt to have their information used by genetic testing companies. Companies like 23andMe have used customer’s data for research to discover therapeutics and come up with hypothesis to make medicines. People can also upload their genetic information to third party websites, such as GEDmatch and DNA.Land, to find long-lost relatives.
With these scenarios, the data is used for good but what about the opposite? The situation can easily be switched, which could prove harmful for those who work covert operations (aka spies) and need their identities to remain secret.
Erlich shared that it takes roughly a day and a half to sift through a dataset of 1.28 million individuals to identify a third cousin. This is especially true for people of European descent in the United States. Then, based on sex, age and area of residence it is easy to get down to 40 individuals. At that point, the information can be used as an investigative lead.
To alleviate the situation and protect people, the researchers propose that raw data should be cryptographically encrypted and only those with the right key can view and use the data.
“Things are complicated but with the right strategy and policy we can mitigate the risks,” said Erlich.
Dean Boyce's statement on amicus brief filed by President Bollinger
President Bollinger announced that Columbia University along with many other academic institutions (sixteen, including all Ivy League universities) filed an amicus brief in the U.S. District Court for the Eastern District of New York challenging the Executive Order regarding immigrants from seven designated countries and refugees. Among other things, the brief asserts that “safety and security concerns can be addressed in a manner that is consistent with the values America has always stood for, including the free flow of ideas and people across borders and the welcoming of immigrants to our universities.”
This recent action provides a moment for us to collectively reflect on our community within Columbia Engineering and the importance of our commitment to maintaining an open and welcoming community for all students, faculty, researchers and administrative staff. As a School of Engineering and Applied Science, we are fortunate to attract students and faculty from diverse backgrounds, from across the country, and from around the world. It is a great benefit to be able to gather engineers and scientists of so many different perspectives and talents – all with a commitment to learning, a focus on pushing the frontiers of knowledge and discovery, and with a passion for translating our work to impact humanity.
I am proud of our community, and wish to take this opportunity to reinforce our collective commitment to maintaining an open and collegial environment. We are fortunate to have the privilege to learn from one another, and to study, work, and live together in such a dynamic and vibrant place as Columbia.
Sincerely,
Mary C. Boyce
Dean of Engineering
Morris A. and Alma Schapiro Professor