
Advancing Robotics with the Power of Touch
Computer scientists introduce a novel system that mimics human tactile sensing capabilities in robots.
Computer scientists introduce a novel system that mimics human tactile sensing capabilities in robots.
Researchers from the department presented their work at the Conference on Robot Learning (CoRL) in Munich, Germany. Since its inception in 2017, CoRL has promoted pioneering research and innovative applications at the intersection of robotics and machine learning, showcasing groundbreaking advancements in these dynamic fields.
D$^3$Fields: Dynamic 3D Descriptor Fields for Zero-Shot Generalizable Rearrangement
Yixuan Wang Columbia University, Mingtong Zhang University of Illinois, Urbana-Champaign, Zhuoran Li National University of Singapore, Tarik Kelestemur Boston Dynamics AI Institute, Katherine Rose Driggs-Campbell University of Illinois, Urbana-Champaign, Jiajun Wu Stanford University, Li Fei-Fei Stanford University, Yunzhu Li Columbia University
Abstract:
Scene representation is a crucial design choice in robotic manipulation systems. An ideal representation is expected to be 3D, dynamic, and semantic to meet the demands of diverse manipulation tasks. However, previous works often lack all three properties simultaneously. In this work, we introduce 3D Fields—dynamic 3D descriptor fields. These fields are implicit 3D representations that take in 3D points and output semantic features and instance masks. They can also capture the dynamics of the underlying 3D environments. Specifically, we project arbitrary 3D points in the workspace onto multi-view 2D visual observations and interpolate features derived from visual foundational models. The resulting fused descriptor fields allow for flexible goal specifications using 2D images with varied contexts, styles, and instances. To evaluate the effectiveness of these descriptor fields, we apply our representation to rearrangement tasks in a zero-shot manner. Through extensive evaluation in real worlds and simulations, we demonstrate that 3D Fields are effective for zero-shot generalizable rearrangement tasks. We also compare 3D Fields with state-of-the-art implicit 3D representations and show significant improvements in effectiveness and efficiency. Project page: https://robopil.github.io/d3fields/
3D-ViTac: Learning Fine-Grained Manipulation with Visuo-Tactile Sensing
Binghao Huang Columbia University, Yixuan Wang Columbia University, Xinyi Yang University of Illinois, Urbana-Champaign, Yiyue Luo University of Washington, Yunzhu Li Columbia University
Abstract:
Tactile and visual perception are both crucial for humans to perform fine-grained interactions with their environment. Developing similar multi-modal sensing capabilities for robots can significantly enhance and expand their manipulation skills. This paper introduces 3D-ViTac, a multi-modal sensing and learning system designed for dexterous bimanual manipulation. Our system features tactile sensors equipped with dense sensing units, each covering an area of 3mm2. These sensors are low-cost and flexible, providing detailed and extensive coverage of physical contacts, effectively complementing visual information. To integrate tactile and visual data, we fuse them into a unified 3D representation space that preserves their 3D structures and spatial relationships. The multi-modal representation can then be coupled with diffusion policies for imitation learning. Through concrete hardware experiments, we demonstrate that even low-cost robots can perform precise manipulations and significantly outperform vision-only policies, particularly in safe interactions with fragile items and executing long-horizon tasks involving in-hand manipulation. Our project page is available at https://binghao-huang.github.io/3D-ViTac/.
RoboEXP: Action-Conditioned Scene Graph via Interactive Exploration for Robotic Manipulation
Hanxiao Jiang Columbia University, Binghao Huang Columbia University, Ruihai Wu Peking University, Zhuoran Li National University of Singapore, Shubham Garg Amazon, Hooshang Nayyeri Amazon, Shenlong Wang University of Illinois, Urbana-Champaign, Yunzhu Li Columbia University
Abstract:
We introduce the novel task of interactive scene exploration, wherein robots autonomously explore environments and produce an action-conditioned scene graph (ACSG) that captures the structure of the underlying environment. The ACSG accounts for both low-level information (geometry and semantics) and high-level information (action-conditioned relationships between different entities) in the scene. To this end, we present the Robotic Exploration (RoboEXP) system, which incorporates the Large Multimodal Model (LMM) and an explicit memory design to enhance our system’s capabilities. The robot reasons about what and how to explore an object, accumulating new information through the interaction process and incrementally constructing the ACSG. Leveraging the constructed ACSG, we illustrate the effectiveness and efficiency of our RoboEXP system in facilitating a wide range of real-world manipulation tasks involving rigid, articulated objects, nested objects, and deformable objects. Project Page: https://jianghanxiao.github.io/roboexp-web/
Dynamic 3D Gaussian Tracking for Graph-Based Neural Dynamics Modeling
Mingtong Zhang University of Illinois, Urbana-Champaign, Kaifeng Zhang Columbia University, Yunzhu Li Columbia University
Abstract:
Videos of robots interacting with objects encode rich information about the objects’ dynamics. However, existing video prediction approaches typically do not explicitly account for the 3D information from videos, such as robot actions and objects’ 3D states, limiting their use in real-world robotic applications. In this work, we introduce a framework to learn object dynamics directly from multi-view RGB videos by explicitly considering the robot’s action trajectories and their effects on scene dynamics. We utilize the 3D Gaussian representation of 3D Gaussian Splatting (3DGS) to train a particle-based dynamics model using Graph Neural Networks. This model operates on sparse control particles downsampled from the densely tracked 3D Gaussian reconstructions. By learning the neural dynamics model on offline robot interaction data, our method can predict object motions under varying initial configurations and unseen robot actions. The 3D transformations of Gaussians can be interpolated from the motions of control particles, enabling the rendering of predicted future object states and achieving action-conditioned video prediction. The dynamics model can also be applied to model-based planning frameworks for object manipulation tasks. We conduct experiments on various kinds of deformable materials, including ropes, clothes, and stuffed animals, demonstrating our framework’s ability to model complex shapes and dynamics. Our project page is available at \url{https://gaussian-gbnd.github.io/}.
ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation
Wenlong Huang Stanford University, Chen Wang Stanford University, Yunzhu Li Columbia University, Ruohan Zhang Stanford University, Li Fei-Fei Stanford University
Abstract:
Representing robotic manipulation tasks as constraints that associate the robot and the environment is a promising way to encode desired robot behaviors. However, it remains unclear how to formulate the constraints such that they are 1) versatile to diverse tasks, 2) free of manual labeling, and 3) optimizable by off-the-shelf solvers to produce robot actions in real-time. In this work, we introduce Relational Keypoint Constraints (ReKep), a visually-grounded representation for constraints in robotic manipulation. Specifically, ReKep are expressed as Python functions mapping a set of 3D keypoints in the environment to a numerical cost. We demonstrate that by representing a manipulation task as a sequence of Relational Keypoint Constraints, we can employ a hierarchical optimization procedure to solve for robot actions (represented by a sequence of end-effector poses in SE(3)) with a perception-action loop at a real-time frequency. Furthermore, in order to circumvent the need for manual specification of ReKep for each new task, we devise an automated procedure that leverages large vision models and vision-language models to produce ReKep from free-form language instructions and RGB-D observation. We present system implementations on a mobile single-arm platform and a stationary dual-arm platform that can perform a large variety of manipulation tasks, featuring multi-stage, in-the-wild, bimanual, and reactive behaviors, all without task-specific data or environment models.
GenDP: 3D Semantic Fields for Category-Level Generalizable Diffusion Policy
Yixuan Wang Columbia University, Guang Yin University of Illinois, Urbana-Champaign, Binghao Huang Columbia University, Tarik Kelestemur Boston Dynamics AI Institute, Jiuguang Wang Boston Dynamics AI Institute, Yunzhu Li Columbia University
Abstract:
Diffusion-based policies have shown remarkable capability in executing complex robotic manipulation tasks but lack explicit characterization of geometry and semantics, which often limits their ability to generalize to unseen objects and layouts. To enhance the generalization capabilities of Diffusion Policy, we introduce a novel framework that incorporates explicit spatial and semantic information via 3D semantic fields. We generate 3D descriptor fields from multi-view RGBD observations with large foundational vision models, then compare these descriptor fields against reference descriptors to obtain semantic fields. The proposed method explicitly considers geometry and semantics, enabling strong generalization capabilities in tasks requiring category-level generalization, resolving geometric ambiguities, and attention to subtle geometric details. We evaluate our method across eight tasks involving articulated objects and instances with varying shapes and textures from multiple object categories. Our method demonstrates its effectiveness by increasing Diffusion Policy’s average success rate on \textit{unseen} instances from 20% to 93%. Additionally, we provide a detailed analysis and visualization to interpret the sources of performance gain and explain how our method can generalize to novel instances. Project page: https://robopil.github.io/GenDP/
Dreamitate: Real-World Visuomotor Policy Learning via Video Generation
Junbang Liang Columbia University, Ruoshi Liu Columbia University, Ege Ozguroglu Columbia University, Sruthi Sudhakar Columbia University, Achal Dave Toyota Research Institute, Pavel Tokmakov Toyota Research Institute, Shuran Song Stanford University, Carl Vondrick Columbia University
Abstract:
A key challenge in manipulation is learning a policy that can robustly generalize to diverse visual environments. A promising mechanism for learning robust policies is to leverage video generative models, which are pretrained on large-scale datasets of internet videos. In this paper, we propose a visuomotor policy learning framework that fine-tunes a video diffusion model on human demonstrations of a given task. At test time, we generate an example of an execution of the task conditioned on images of a novel scene, and use this synthesized execution directly to control the robot. Our key insight is that using common tools allows us to effortlessly bridge the embodiment gap between the human hand and the robot manipulator. We evaluate our approach on 4 tasks of increasing complexity and demonstrate that capitalizing on internet-scale generative models allows the learned policy to achieve a significantly higher degree of generalization than existing behavior cloning approaches.
Differentiable Robot Rendering
Ruoshi Liu Columbia University, Alper Canberk Columbia University, Shuran Song Stanford University, Carl Vondrick Columbia University
Abstract:
Vision foundation models trained on massive amounts of visual data have shown unprecedented reasoning and planning skills in open-world settings. A key challenge in applying them to robotic tasks is the modality gap between visual data and action data. We introduce differentiable robot rendering, a method allowing the visual appearance of a robot body to be directly differentiable with respect to its control parameters. Our model integrates a kinematics-aware deformable model and Gaussians Splatting and is compatible with any robot form factors and degrees of freedom. We demonstrate its capability and usage in applications including reconstruction of robot poses from images and controlling robots through vision language models. Quantitative and qualitative results show that our differentiable rendering model provides effective gradients for robotic control directly from pixels, setting the foundation for the future applications of vision foundation models in robotics.
Columbia computer scientists work with the Toyota Research Institute to make advanced home robots a reality.
In the Columbia Artificial Intelligence and Robotics (CAIR) Lab, Cheng Chi stands in front of a robotic arm. At the end of the arm sits a yellow plastic cup. His goal at the moment is to use a piece of rope to hit the cup to the ground.
“I never thought I would have to do this as part of a research project,” said Chi, a second-year PhD student. He was conducting the exercise to gain a better understanding of physical movement and how it can be applied to a robotic control system.
Existing robotic systems struggle to precisely manipulate objects with complex dynamics, such as hitting a small target with a whip or swinging tablecloths to an exact location. While these tasks are quite hard even for humans, we usually have a good intuition about how to change our actions after a failed attempt, and iteratively get closer to the goal.

Chi was able to knock the cup off after five tries. Now, it’s the robot’s turn to fling the piece of rope. It takes the robot four times to hit the target during the experiment (in general less than 10 times). The algorithm/neural network was trained in a simulator using a large amount of data. The robot, called Oolong, had to hit a target and was tested on different kinds of ropes it had never seen before.
Together with Assistant Professor Shuran Song and colleagues from the CAIR Lab, Chi worked to formalize this intuition into an algorithm called Iterative Residual Policy (IRP), a general learning framework for repeatable tasks with complex dynamics where a single model was trained using inaccurate simulation data. IRP can learn from that data and hit many targets with unfamiliar ropes in real robotic experiments, reaching sub-inch accuracy, and demonstrating its strong generalization capability.
This research brings robots from factories, where everything is rigid and can be accurately modeled, closer to everyday households filled with dirty laundry, raw vegetables to be washed in the sink, and leftover food to be cleaned from the fridge. It could potentially alleviate the labor shortage in food, retail, and logistics due to the aging population in many parts of the world. This could also enable the automation of simple tasks like changing bed sheets and badges in hospitals with infectious disease patients.
The team won a Best Paper Award at the Robot Science and Systems Conference (RSS 2022). We caught up with Chi to find out more about his research and PhD life at Columbia.
This is part of a grant from the Toyota Research Institute on deformable object manipulation. For this specific project, I wanted to explore more complex and dynamic forms of robotic manipulation and control. As the primary researcher of this project, I decided on the research topic, problem, and task.
The project started in May 2021. I did a lot of research about control theory for underactuated systems, chaos, and how to work with robot hardware.
Classical robotics literature divides the operation of a robot into three stages — perception, planning, and control. In my previous research, I studied perception and the planning stage of robotics. However, I realized that my knowledge still has a noticeable hole in control theory and systems that control the function and movement of robots.
I believe that I will never become a full-fledged roboticist without understanding all parts of robotic operations. Therefore, I intentionally steered this project toward control which allows me to read more into control-related literature and classes.
For example, I went over the YouTube recording of MIT’s underactuated robotics, taught by Professor Russ Tedrake, who has been known for his contributions to the control of locomotion systems (such as Boston Dynamic’s quadruped robots).
Another interesting thing about control is that, unlike planning, the control of the human body mostly happens at a subconscious level. Therefore, understanding more about control also gave me more insight into how the human body works.
The key realization came after months of reflecting on how I achieved certain tasks and how to formulate such a problem.
Since the relatively early stage of this project (after I decided to tackle the rope whipping task), I had this lingering feeling that being able to adjust the next action based on the error of my previous action is critical for how humans accomplish this task (by observing myself doing it). But I wasn’t able to connect it with math and concrete algorithms.
The next few months were spent playing with data collected in simulations to understand the structure of this task and problem. I often spent a few afternoons a week just staring at my iPad notes, sketching potential algorithms that can solve this task efficiently. Most of them were futile. However, one afternoon in late September, I suddenly came up with the idea that connects my lingering feeling to this concrete algorithm. And the rest was mostly planning out experiments, executing, and verifying results.
I decided on the research project jointly on what is missing in the field and what I wanted to learn. For example, I wanted to get into control last summer, so I took classes online and read relevant papers to build a foundation. I noticed that the missing piece in the field is deformable manipulation with precision.
Existing robotic algorithms often assume the object being manipulated is rigid, and ignore its physics/dynamics, due to its complexity. My research thrust has been targeting this complexity (of object physics and non-rigidity) head-on, which hopefully will result in better algorithms that will improve the overall performance and robustness of robotics systems, outside of confined/structured industrial environments.
Whipping a piece of rope is one of the simplest instances of dynamic deformable object manipulation, without the additional perceptive complexity such as self-occlusion, etc. However, we believe that whipping a piece of rope and tablecloth is representative of the class of problem we are interested in and that there is no existing robotic system/algorithm that can accomplish this task. Therefore, our algorithm has expanded what is considered possible in robotics.
I thought that it would be cool to simplify it to a minimum-working task, like whipping. Whipping a piece of rope or cloth accurately requires adapting existing skills which humans are good at but it is very difficult for robots to do.
Humans can hit targets with reasonable accuracy after usually 10~20 trials. The best algorithm before IRP takes 100-1000+ trials to get there.
The project spanned 10 months and it was not easy, since solving this novel and challenging task requires going beyond the common paradigm in the field, for example, reinforcement learning or system identification.
I tried three ideas at first and none of them worked or advanced the field to a satisfying degree for me. The final idea was inspired by some studies from the biomechanics/neural science community that I came across while doing research.
While I was struggling with this project, my advisor pointed me to this recording of an RSS 2020 workshop. I was fascinated by one of the talks by Professor Dagmar Stenard and her findings from the biomechanical perspective of how humans minimize uncertainty and avoid the chaotic region of the state space when taking actions.
I read further into her publications and was pleasantly surprised that her group was studying the same rope-whipping problem. Their algorithm was crude and they only tested in simulation with many additional assumptions, but I really liked their problem formulation of the whipping task and their use of action primitive, which dramatically reduced the number of parameters needed to describe the dynamic and continuous robot action.
They also demonstrated that their action primitives (that bio literature believes humans also use) are sufficient for this task. Therefore, I took their problem formulation and tweaked their action primitive to better fit real robotic hardware, and eventually developed the IRP algorithm on top of that.

The type of rope we simulated for training is modeled after a thick cotton rope we bought on Amazon. However, due to the various complex physical properties and their effects, the rope modeled in simulation behaves significantly differently from its real-world counterpart. This is an instance of a well-known challenge in the robotics community called “sim2real gap”.
Since the deep-learning revolution (~2014), a large body of robotic algorithms emerged that have shown very promising results in simulated environments. However, they also rely on a large amount of data for training (our algorithm included), which is only feasible to collect in simulation. If the behavior of objects in simulation matches exactly their counterparts in real life, in theory, we can directly apply these data-hungry algorithms to the real world. Unfortunately, this is far from the truth, and the difference is especially big for deformable objects.
The biggest contribution of this paper is providing a solution to close this “sim2real gap” for a limited class of problems (where the actions are repeatable, and the objects can be reset to the original state), i.e. the algorithm behaves just as good in the real world as in simulation, despite the simulation it was trained on is very “wrong”.
To further demonstrate how “wrong” the simulation can be while the algorithm still works, we cut out a long strip of cloth, that behaves like a gymnastic ribbon and treated it as the rope. We also bought a very thick leather bullwhip, that has a non-uniform density (it becomes thinner and thinner as it goes toward the tip), while all ropes we trained in simulation have uniform thickness and density. The experimental results on these two “ropes” were just as good.
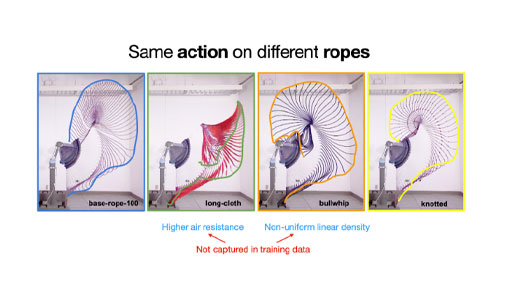
I like how researchers are able to try high-risk ideas that actually advance the field and also learn fundamental knowledge about the field. Working in industry usually constrains research options to low-risk ideas, while the engineering effort might be larger.
I gained my initial research experience during my undergrad at the University of Michigan, working on deformable object perception. I had multiple internships, as well as full-time jobs at autonomous vehicle companies, which taught me how to properly engineer a robotics software system.
I applied to Columbia to work with Assistant Professor Shuran Song. Just before I graduated from undergrad, Shuran did a job talk at the University of Michigan. My undergrad research advisor Professor Dmitry Berenson was at her talk and he was really impressed. Berenson strongly recommended that I apply to work with her and he thought we would be a great fit. After researching her past publications, I did find a large overlap in our research interests and I only heard good words about her after asking other people who have worked with her.
At the time, I wasn’t really sure about getting a PhD, and because of the time needed to complete the applications, I only applied to two schools. The application website could have been improved, but the overall process is surprisingly smooth. I really like the idea that students are admitted by and to individual professors, and the professors make the decision.
The highlight of my time is being able to be taught and guided by my advisor, as well as other PhD students.
I think what improved the most was to think more structurally and not be buried by the details. Due to the engineering complexity of robotic systems, there are thousands of variables and decisions, large and small, I needed to make for the project to progress. For example, on the high level, how to model the rope in the simulation, how to model the robot, how to represent the observation and actions, how the model should be architected, etc.
For an inexperienced researcher like myself, it is not obvious which one of these parameters will make or break the project, or will only yield a small change in the final performance. So, I over-analyzed, over-engineered, and over-thought the small problems. Fortunately, Shuran often called out that some of these decisions probably don’t matter that much, and choosing an arbitrary path to go forward is strictly better than spending time thinking about which one is better.
The problem is that this is mostly based on intuition. Shuran can’t always give evidence of why one thing doesn’t matter and why another does. But fortunately, I think I am getting a better grasp of these intuitions. It will become easier for me as time passes and I become an expert in robotics.
I also have found that it is really important to communicate clearly, both in meetings and when writing things down for reports or even emails. Learning by example from my advisor also helps a lot.
New students going into research should try as hard as possible to push through the first research project. It is always hard in the beginning, and it might feel impossible, but you can do it. Build up a tolerance for failure and continue to try different things, which is often critical to making a contribution to the field.
Roboticist’s proposed framework to enable robots to learn on their own and adapt to new environments could revolutionize everything from home service robots to emergency response systems.